
Data gravity and the laws of scale
The motivation for data-less (micro) services is found in data gravity, the laws of scale and a doze of thermodynamics. All of them a mouthful in their own way, so lets begin.
Data gravity describes how data attracts data in the same way as celestial bodies attracts each other. The more data there is, the stronger the pull. Data gravity has the power to tranform the best architected software systems into unmanageable balls of mud (data & code). What is less understood is data gravity’s underpinning cause that, my claim, can be traced to the universal laws of scale as outlined by professor Geoffrey West in his book Scale, the universal laws of life and death in organisms, cities and companies. For those who do not have the time to read the book, watch one of his many online talks.
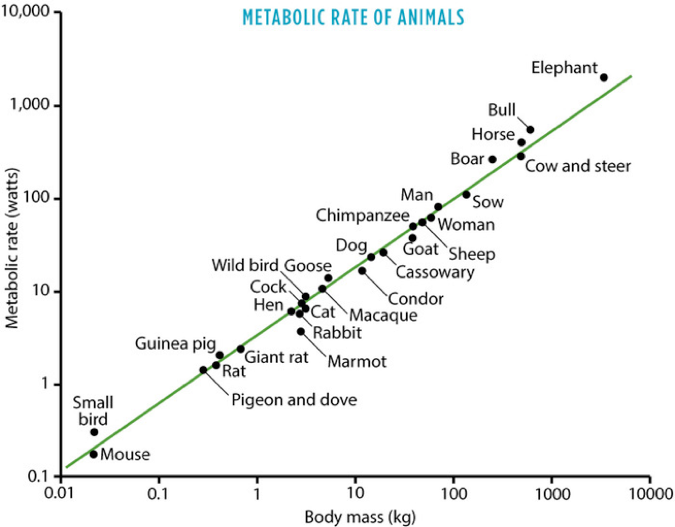
In biology each doubling of size leads to an 75% efficiency gain. The effect being that an elephant burn fewer calories pr. kg than a human, who in turn burn less than a mouse as illustrated below.
Cities follow the same pattern, but with the factor of 85%. Basically does a big city have fewer gas stations pr inhabitant than a small one. Another aspect is the super-linear scaling of innovation, wages, crime etc that comes from the social networks. This grows with a factor of 15% pr doubling in size.
According to professor West the scaling effects are caused by the fractal nature of the infrastructure that provides energy and removes waste. Think about the human circulatory system and the water, sewage, and gas pipes in cities. I am convinced the same laws apply for software system development, though with different and yet unknown factors.
Last but not least, software development as any activity that uses energy to create order will cause disorder somewhere else. This is due the the second law of thermodynamics. This mean that we need to carefully decide where we want order and how we can direct disorder to places where harm can be minimised.
Data less services:
Data-less services is the natural result of acknowledging the wisdom of the old saying that data ages like wine, software like fish. The essence being that software, the code, the logic, and the technology deteriorate with time, while data can be curated into something more valuable with time.
Therefore it make sense to keep code and data separated. Basically, to separate fast moving code from the slow moving data as a general design strategy. Another way of viewing this is to regard data the infrastructure that scale sub-linear, while the code follows the super-linear growth of innovation.
At first glance this might look like a contradiction in context of the micro-service architectural style that advocates small independent autonomous services. But when we acknowledge that one of the problems with micro-services is sacrificed data management it might make sense.
It is also worth mentioning that separation of code from data is at the heart of the rational agent model of artificial intelligence as outlined in Russel & Norvig’s seminal book Artificial Intelligence: A modern approach where an agent can be anything that can perceive and act upon its environment using sensors and actuators.
A human agent have eyes, ears and other organs for sensing, and hands, legs and voice as actuators. A robotic agent uses a camera, radar or lidar for sensing and actuates tools using motors. A software agent receives files, network packages, keyboard inputs as its sensory inputs and acts upon its environment by creating files, displaying information, sending information to other agents and so on.
The environment could be anything, from the universe to the stock market in Sidney, or a patients prostata that undergo surgery. It can be a physical reality or a digital representation of the same. The figure below shows agent and its environment. An agent consists of logic and rules and the environment consists of data.

The internal function of the agent is known as its perception-action cycle. This can be dumb as in a thermostat or highly sophisticated as in a self driving car. While agent research is about the implementation of the perception-action cycle we chose to look at the environment and the tasks the agent need to perform to produce its intended outcomes in that environment.
If the agent is a bank clerk and the environment a customer account, the agent need to be able to make deposits, withdrawals and account statements showing the balance. The environment need to contain the customer and the account. Since the protocol between agent and environment is standardised by an API, agent instances can be replaced by something that is more sophisticated that can take advantage of a richer environment. The customer account represents a long lived asset for the bank and it can be extended to cover loans as well as funds.
This approach is also known as the Blackboard Pattern.
Conclusion
Since Information systems are governed by gravity and the laws of scale they are hard to conquer since it at any crossroad is so much easier to extend something that exists then building something new from scratch. Hard enforcement of physical boundaries using micro-services comes with caveats. One being distributed data management, another being that each micro-service will begin to grow in size as new features are needed and therefore require continuous shepherding and fire extinguishing as the entropy materialises.
The proposed approach is to address this using a data-less service architecture that is supported by a shared data foundation in the same way as agents and environment using the blackboard pattern. This mean to implement an architectural style that builds on the old saying that code ages like fish and data ages like wine.
This is by the way the pattern of the OSDU Data Platform that will be addressed in a later post.
