The OSDU® Data Platform (hereafter called “the data platform”) has evolved a lot since The OSDU® Data Platform – A Primer was written back in January 2023. It has more than enough functionality that can be used, and it is commercially available from your favourite cloud service provider.
The intent with this blogpost is to explore and expand our thinking on the role of a data platform as a key component in a larger digital ecosystem.
Recap of core concepts
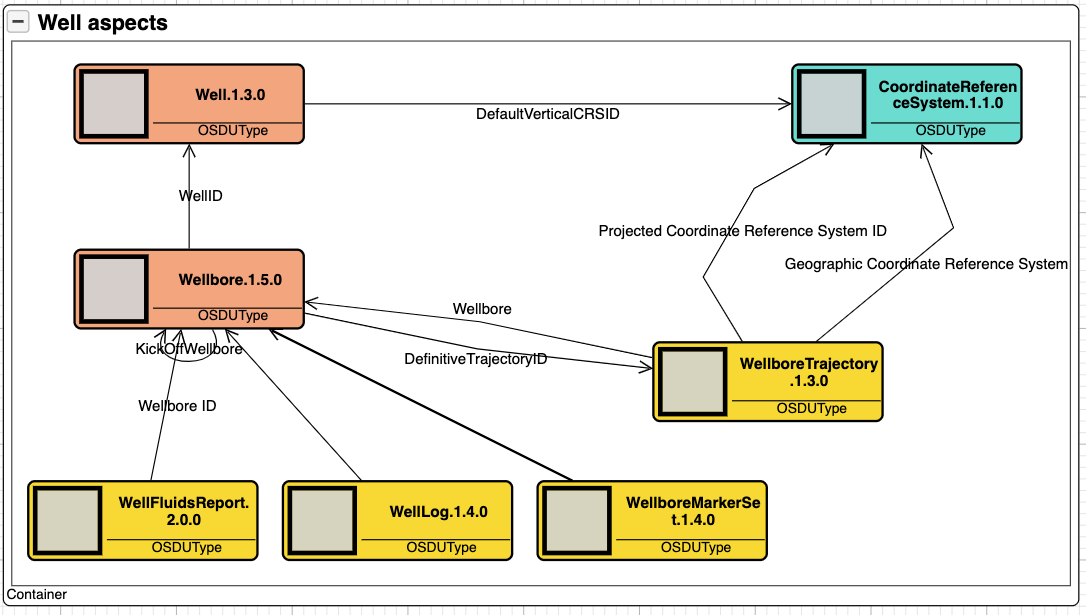
The foundation of the data platform is the data classification schema and design philosophy that is illustrated by using entities from the wells domain (figure 1). Master data objects are orange, reference data is turquoise, and work product components are yellow.
Master data entities represents real world things or concepts that have lifecycles. It is possible to think about master data entities as scaffolding’s or coat hangers, i.e., as object that act as the conceptual bearers in a domain. Work product components provide meta data about datasets that are connected to the actual master entities. Example, when a new fluids report is made and ingested into the data platform, a new fluids report work-product-component entity instance is made and connected to the actual wellbore.
Reference data represent concepts that are stable over time such as coordinate reference systems, units of measure, and various codifications such as country codes. Reference data are often defined by standards and might includes transformation services such as going from metric to imperial units and vice versa. The data platform has a rich set of reference data structures defined, the Coordinate Reference System (CRS) being one of them.
Figure 1: Data concepts in the wells domain
Figure 1 tells the reader that the wells domain has two concepts; well and wellbore. That all wells are geolocated and that the wellbore is the aggregator of associated datasets such fluid reports, logs, markers and trajectories. Lastly that trajectories come with some additional features that we leave as is for now.
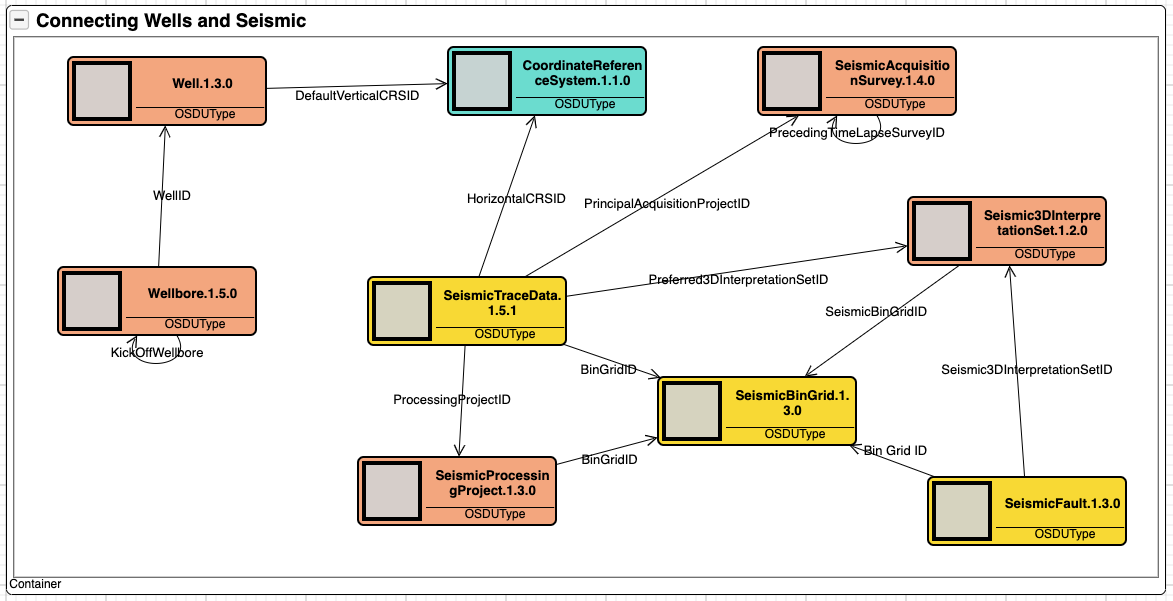
Figure 2 shows how independent domains such as wells and seismic can be related by use of geolocation (CRS). This is extremely useful when we want to know what wells exist in an area covered by a seismic survey.
We can also see how the seismic domain is organised into three fundamental concepts; the acquisition survey; the processing project; and the interpretation set. Further, that the seismic domain consists of three data sets; trace data, bin grids and interpreted faults. What these concepts mean is out of scope as there are much more to both wells and seismic than shown here. Finally, these two figures shows the value of visualisation when exploring the data platform. The tool used is Kava’s AKM Modeller.
Figure 2: Connecting domains through geolocation
The OSDU® data models covers most of the subsurface work. Beginning with seismic acquisition, processing and interpretation. Crossing into structural and dynamic earth modelling, field development planning, well architecting and delivery, including geological and petrophysical evaluation. Further down the road we find production planning and optimisation where the current support is limited.
The subsurface data models are now so good that the mining industry has started to explore them. It should not take much fantasy to see how the data platform can be extended into adjacent domains that manage geolocated hazards and assets. Examples include civil infrastructure such as railroad tracks, roads, water and energy infrastructure, or for that matter, medical records about patients, deceases, and treatments. The key being its easier to repurpose something that works than starting from scratch.
Data work
So far the thinking and discussions about the OSDU® Data Platform has been as a technical product that create value through its existence. In many ways this viewpoint has served us well during development of the technical capabilities, but it might fall short when we want to understand how does it create value for the end user organisations.
The catch of cause is that the data platform does not exist in a vacuum. To create value for its users, they be oil and gas companies or software companies the data platform will be part of a larger functional information system. An information system is much more than its technological components. Literature defines an information system as a formal socio-technical, organisational system designed to collect, process, store and distribute information. From this definition is it obvious that it is a complete different task to develop and implement an information system than developing its technical components.
One way to better understand an information system is by exploring data work, and how such work unfolds in an industrial context. Here will we lend ourself on the work done by the NTNU researchers Parmiggiani et al that is captured in their 2022 article In the Backrooms of Data Science where we can read:
“Much Information Systems research on data science treats data as pre-existing objects and focuses on how these objects are analyzed. Such a view, however, overlooks the work involved in finding and preparing the data in the first place, such that they are available to be analyzed. In this paper we draw on a longitudinal study of data management in the oil and gas industry to shed light on this backroom data work. We find that this type of work is qualitatively different from the front-stage data analytics in the realm of data science, but is also deeply interwoven with it. We show that this work is unstable and bidirectional. That is, the work practices are constantly changing and must simultaneously take into account both what data it might be possible to get hold of as well as the potential future uses of the data. It is also a collaborative endeavour, involving cross-disciplinary expertise, that seeks to establish control over data and is shaped by the epistemological orientation of the oil and gas domain”.
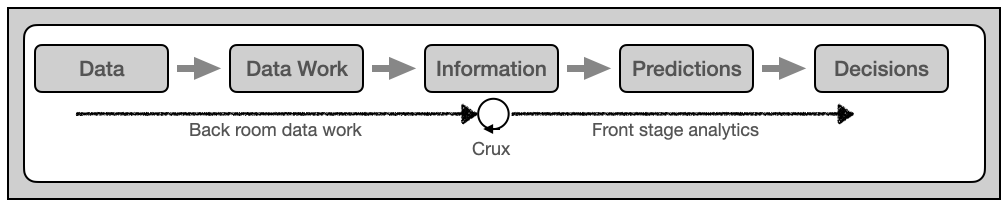
Based on these findings should we begin to think about the OSDU® Data Platform as a component in an information system that support industrial asset lifecycle management and the decision making related to those assets. In such context data work is fundamental for the decision making (figure 3).
Figure 3: From data to decision
The primary function of back room data work is to turn data into information that is fit for purpose for front stage analytics aka data science aka machine learningand AI (Artificial Intelligence). I have deliberately replaced the word analytics by prediction in figure 3. The reason is professor Ajay Agrawal‘s 2017 statement that the value of AI is reduced prediction cost. Cheaper predictions provides options, and options is what is judged when decisions are made.
Predictions and options are the workhorses of decision making, and subsurface workflows, done by hand or machine is fundamentally about prediction options. We don’t know if a formation contain hydrocarbons before a well has been drilled. And even when it’s drilled the reservoir might be missed by a meter or two. The more an option is backed by quality data the higher probability for success.
This means that the back room data work boils down to implementing the data stewardship that enables the best possible information given the data at hand. It’s directly connected to the prediction making that is based on the information we have, and the underpinning causal relationships that governs the physical world we are part of (liquids flow downwards due to gravity).
In situations we do not have enough information are we left with three options. 1) make the decision on the information we have, and accept the uncertainty. 2) acquire more data if possible. 3) use additional data we have to create a richer foundation. This is where the epistemologicalnature of data work materialise. What additional information can we include and what does that additional information bring to the table with respect to the probability for our hypothesis beeing correct or wrong? This takes us directly to Bayes rule and causal inference, concepts that sits at the core of AI.
The data work challenge can therefore be wrapped up as a need for good data stewardship, and data stewardship requires tools and practice. The OSDU® Data Platform is a tool that enables creation of an information system that simplifies data stewardship, an information system that systematically transform the organisation data into a high value trusted information assets for its users.
Separation of concern is a key design principle. Just like our homes have different rooms for different purposes. In computer science, seperation of concern leads to modularization, encapsulation, and programming language constructs like functions and objects. It’s also behind software design patterns like layering and model-view-controller (MVC).
The importance of breaking software down into smaller loosley coupled parts with high cohesion have been agreed for decades. Yourdon & Constantine’s 1978 book Structured Design: Fundamentals of a Discipline of Computer Program and System Design provides fundamental thinking on the relationships between coupling, cohesion, changability and software system lifecycle cost.
Modularization begins with the decomposition of the problem domain. For digital information systems (software) it continues with identification of abstractions that match both the problem domain and the execution machinery, and the packaging of these abstractions into working assemblies aka applications that can run on a computer.
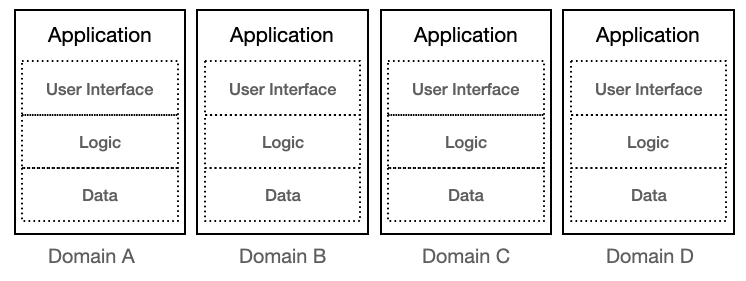
Figure 1: Applications serving multiple domains
Figure 1 shows that each application addresses three concerns: the user interface, the functional logic, and its data. While software architects talk about their systems using such strict layering, everybody who have looked inside a real-world applications know reality is much more muddy.
What figure 1 does not show is how a company is divided into different areas, and how these areas are used to define which applications are responsible for which tasks. It also doesn’t explain how information can be exchanged between applications, and it doesn’t illustrate how data gravity corrupts even the best design as time goes by. That what began as a well-defined application over years becomes an entangled unmanagable behemoth.
Separating the wrong concerns?
When we try to figure out why certain things are missing, we need to ask a key question about how we design business applications: Are we dividing things up in the best way? To answer this, we have to think about the different factors at work and consider different ways to deal with them.
Data gravity captures the hard fact that data gravitates data. Why this is so has many reasons. Firstly, it’s always easier to extend an existing database with a new table than making a new one from scratch. The new table can leverage the values of existing tables in that database. In other words, it makes data exchange simpler. Finally, the energy cost of adding a new table is lower than the energy cost of creating a complete new database and establishing required exchange mechanisms.
Enterprises are complex systems without boundaries. Organisational charts show how the enterprise is organized into verticals such as sales, engineering, and manufacturing, verticals that are served by horizontals such as IT and finance and control. In reality, the enterprise is a web of changing interactions that continuously consume and produce data. Mergers, divestments, and reorganizations change the corporate landscape continuously, adding to the underpinning complexity.
Applications are snapshots of the enterprise. They represent how the enterprise works at a given point in time and as such, they are pulled apart by data gravity on one side and the enterprise dynamics on the other. This insight is captured by the old saying that data ages as wine, and software ages as fish. Using the wine and fish analogy, applications are best described as barrels with fish and wine.
The effects of these forces play over time is entangled monolithic behemoth applications that are almost impossible to change and adapt to new business needs. The microservices architectural style was developed to deal with this effect.
Microservices
Microservices is based on decomposing the problem space into small independent applications that communicates using messaging. The approach is reductionistic and driven by development velocity. One observed effect is distributed data management, and they does not solve the underpinning problem of data and software entanglement.
The specific relevant content for this request, if necessary, delimited with characters: Sticking to the fish analogy, microservices enable us to create small barrels that contain Merlot and salmon, Barbera and cod, and Riesling and shark, or whatever combination you prefer. They do not separate data from the code, quite the opposite, they are based on data and software entanglement.
The history of the microservice architectural style goes back to 2011-2012, and for the record, the author was present at the 2011 workshop. It’s also important to mention that the style has evolved and matured since its inception, and it is not seen as a silver bullet that solves everything that is bad with monoliths. It’s quite the opposite; microservices can lead to more problems than they solve.
To get a deeper and more profound understanding of microservices read Software Architecture: The Hard Parts and pay attention to what is defined as architectural quanta: an independently deployable artifact with high functional cohesion, high static coupling, & synchronous dynamic coupling. The essence of an architectural quanta is independent deployment of units that perform a useful function. A quanta can be built from one or many microservices.
Introducing the library architectural style
The proposed solution to the problems listed above is to separate data from applications and to establish a library as described in the reinventing the library post, and to call this the library architectural style as illustrated by figure 2 below.
The essence of the library style is to separate data from the applications and to provide a home for the data and knowledge management services that are often neglected. The library style is compatible with the microservice style, and in many ways strengthens it as the individual microservice is relieved from data management tasks. The library itself can also be built using microservices, but it’s important that it’s deployed as independent architectural quanta(s) from the application space, which are quantas of their own.
Figure 2: Separating applications from data by adopting the library architectural style
There are many fators that make implementation of a functional library difficult. Firstly, all data stored in the library must conform to the libraries data definitions. Secondly, the library must serve two conflicting needs. The verticals need for efficient work and easy access to relevant data, and the library’s own needs for data inventory control, transformations and processing of data into consumable insigthts and knowledge.
The library protocol
A classical library lending out books provide basically four operations to its users:
Search i.e., what books exist, their loan status, and where (rack & shelf) they can be found.
Loan i.e., you take a book and register a loan.
Return i.e., you return the book and it’s placed back by the librarian.
Wait i.e., you register for a book to borow and are notified when it’s available.
These operations constitute the protocol between the library and its user, e.g., the rules and procedures for lending out books. In the pre-computer age, the protocol was implemented by the librarian using index cards and handwritten lists. The librarians performed in addition many back-office services such as acquiring new books, replacing damaged copies, and interacting with publishers and so on. These services are left out for now.
Linda, Tuple spaces and the Web
In danger of making this a history lesson, but in 1986 David Gelerntner at Yale University released what is called the Linda coordination language for distributed and parallel computing. Linda’s underpinning model is the tuple space.
A tuple space is an implementation of the associative memory paradigm for parallel / distributed computing where the “space” provides repository of tuples i.e., sequences or ordered lists of elements that can be manipulated by a set of basic operations. Sun Microsystems (now Oracle) implemented the tuple space paradigm in their JavaSpace service that provide four basic operations:
write (Entry e, ..): Write the given entry into this space instance
read (Entry tmpl, ..): Read a matching entry from this space instance
take (Entry tmpl, ..): Read an entry that matches the template and remove it from the space
notify(Entry tmpl, ..): Notify the application when a matching entry is written to the space instance
Entry objects – define the data elements that a JavaSpace can store. The strength of this concept is that the JavaSpace can store linked and loosely coupled data structures. Since entries are Java objects, they can also be executed by the readers. This makes it possible to create linked data structures of executable elements. An example being arrays whose cells can be manipulated independently.
JavaSpaces is bound to the Java programming language, something that contributed to its commercial failure. Another factor was that around year 2000 few if any enterprises were interested in parallel/distributed computing, nor were the enterprise software suppliers such as Microsoft, Oracle, SAP, and IBM.
The evolution of the Internet has changed this. The HTTP (Hypertext Transfer Protocol) provides an interface quite similar to the one associated with tuple spaces, though with some exceptions:
GET: requests the target resource state to be transferred
PUT: incurs changes to the target resource state
DELETE: requests a deletion of the target resource state
The main difference is that HTTP is a pure transport protocol between a client and a server, where the client can request access to an addressable resource. A tuple space implements behavior on the server side, behavior that could be made accessible on the Internet using HTTP.
Roy Fielding’s doctoral dissertationarchitectural styles and design of network-based software architectures defines the REST (Representative State Transfer) architectural style that is used by most Web APIs today.
REST provides an abstraction of how hypermedia resources (data, metadata, links, and executables) can be moved back and forth between where they’re stored and used. Most REST implementations use the HTTP protocol for transport but are not bound by it. REST should not be confused with Remote Procedure Calls (RPC) that can also be implemented using HTTP. Distinguishing RESTful from RPC can be difficult; the crux is that REST is bound to access of hypermedia resources.
The JavaSpace API is a RESTful RPC API as its operations are about moving Entry objects between a space and its clients, as shown in figure 3. The implication is that RESTful systems and space-based systems are architecturally close and may be closer than first thought when we explore what a data platform can do.
Data platforms
A data platform is according to ChatGPT a comprehensive infrastructure that facilitates the collection, storage, processing, and analysis of data within an organization. It serves as a central hub for managing and leveraging data to derive insights, make informed decisions, and support various business operations.
The OSDU® Data Platform, as an example, provides the following capabilities:
Provenance aka lineage that tracks the origin of a dataset and all its transformations
Entitlement that ensures that only those entitled have access to data
Contextualisation by sector specific scaffolding structures such as area, field, well, wellbore, survey
Standardised data definitions and APIs
Imutability and versioning as the foundation of provenance and enrichment
Dataset linking by use of geolocations including transformation between coordinate systems
Unit of measure and transformations between unit systems
Adaptable to new functional needs by defining new data models aka schemas
The OSDU® Data Platform is an industry-driven initiative aimed at creating an open-source data platform that standardizes the way data is handled in the upstream oil and gas sector. The platform demonstrates how a library can be built. For more details, it can be found on the OSDU® Forum’s homepage. Those needing a deep-dive are recommended to read the primer part one and two.
The OSDU® Data Platform functions in many ways as a collaborative data space. It can also be understood as a system for learning and transfer of knowledge within and between disciplines. It is in many ways a starting point for developing a digital variant of the ancient library where scribes captured and transformed the knowledge of their time for future use.
From JavaSpaces to DataSpaces
JavaSpaces failed commercially for many reasons outside the scope of this blog post. Despite that, the value of space-based computing lives on in initiatives such as the European Strategy for Data and the European Data Space initiative.
The OSDU® Data Platform has demonstrated that it’s possible to create industry-wide data platforms that can act as the foundation in what can be called the library architectural style. A style that is basically a reincarnation of space-based computing.
The true power of space-based computing disappears in technical discussions related to how to construct the spaces, discussions on who owns what data, and so on. What is lost in those discussions is the simplicity space-based computing offers application developers.
A simplicity that is very well illustrated in this quarter of a century-old picture from Sun Microsystems showing how “Duke the JavaBean” interacts with JavaSpace instances moving elements around.
This is also a good example of how a library works; some create new books that are made available in the library. Others wait for books to read, and others take books on a loan. Others work on the backside, moving books from one section (space) to another, or for that matter, from one library to another.
Figure 3: JavaSpaces at work
Figure 3 illustrates what this blog post started out with, separation of concern and the importance of separating the right concerns. There is a huge potential in decoupling workers (applications) from the inventory management that is better done by a library.
A digression. My soon 25-year-old master thesis demonstrated that a JavaSpace-based implementation of a collaborative business problem was half the size of the solution built with the more traditional technology of the time. That, in many ways, shows the effect of having a data platform in place and the value from separating data from business logic.
The OSDU® Data Platform work has thought us that the development of an industry wide data platform does not come for free and require collaboration on global scale. The OSDU® Data Platform development has also demonstrated that this is possible within one of the most conservative industries of this world, something that mean its doable in other sectors as well. Their benefit beeing that they can stand on the shoulders of what has already been achieved. A working technological framework is made availble for those who want to explore it.
My April 2023 On failed IT projects post did not address the political aspects of large scale IT system acquisition’s. The post is inspired by Dr. Brenda Forman’s chapter on the political challenge found in the book The Art of System Architecting, third edition, a book that is highly recommended.
The book addresses architecting of systems, and since a firms information technology, it be in the private or public sector is a system the systems architecting approach is applicable. For information technology to make any sense its structure must support the firm’s overall mission.
Politics as design factor
The bottom line is: If the politics don’t fly, the system never will. This is the case for any kind of system or technology program that require government funding. From a Norwegian perspective the National Transport Plan is a good example. Projects are moved up and down dependent of political climate. No project on the plan is safe before the funding is in place.
Architects must be able to think in political terms. According to Dr. Forman this mean to understand that political processes follows an entirely different logic than the logic applied by scientists and engineers. Scientists and engineers are trained to marshal their facts and proceed from facts to conclusion.
Political thinking is different, it do not depend on logical proof, but on past experience, negotiation, compromise, and perceptions. Proof is the matter of having the votes. If the majority of votes can be mustered in the parliament the project has been judged to be worthy, useful and beneficial for the nation.
Mustering the votes depends only in part of engineering or technological merit. These are important, but to get the votes on a regular basis depends more on jobs and revenues in electoral districts than technological excellence. It might be more important for an elected representative to have a project that keep local construction contractors engaged for the next five years than the value from the traffic on the road when its completed.
To help architects navigate the rocky political landscape the following heuristics or as they are called in the book, The facts of life:
Politics, not technology, sets the limits of what technology is allowed to achieve.
Cost rules.
A strong, coherent constituency is essential.
Technical problems become political problems.
The best engineering solution are not necessarily the best political solution.
Another observation is that political visions don’t fly without feasible technology and adequate funding. Example: In 2007 Norwegian prime minister Jens Stoltenberg uttered the following in his new year’s speech:
Our vision is that within 7 years we will have in place the technology that make it possible to capture carbon from a power plant.This will be an important break through for Norway and when we succeed the world will follow. This is a big project for the country. It’s our moon landing.
Sixteen years later; the technology does not exist and nobody talks about it. In the end there were no constituency, no funding and no politics to make it happen. The problem with such political dreaming is that it diverge effort and resources from things that could have been done, the small steps of improvement that over time could make a difference.
More troublesome are funded initiatives where the political accepted solution does not solve the operational problem at hand. My first encounter with such situation was back in 1990. A part of Norwegian government should spend a billion NOK (a heck of a lot of money) on computers without having a clue about the software to be run on those computers.
Enterprise information systems find themselves in an ill-structured and even complex problem world. Ill-structured problems are problems where the users don’t understand their needs before they see a solution. Complex problems implies that its deduct a solution from an analytical process. The only practical way to solve such problems is by experimentation. More on that can be found here.
Systems architecting in political sensitive environments is an act of balancing conflicting complex systems. Political processes are complex in their own way and the same said about the operational context shown in figure 1 below.
Figure 1: Systems architecting – an act of balancing conflicting interests
Be aware that the end-users who live their lives in the operational context are not the same as the client paying for the solution in the political context. This is definitively the case in the public sector and its often the case in larger enterprises. To showcase the point lets explore a real world case that has run into trouble.
Case
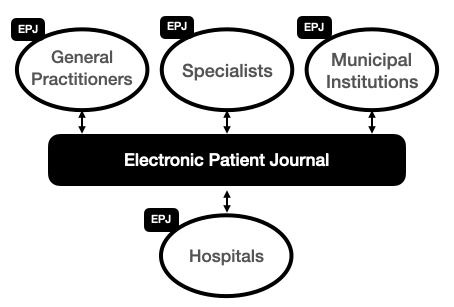
Helseplattformen, is a large scale, highly complex health care IT project that according to the press suffers from cost overruns, delays and severe quality issues. Helseplattformen decided to acquire a commercial product from Epic Systems for what under any circumstance is a ambitious functional scope. A shared patient record across hospitals, general practitioners, specialists and municipal institutions in one of Norway’s health regions.
Reported problems included lost data, record lockings, cumbersome user interfaces and general instability, all leading to patient safety concerns. The fact that users in Denmark, UK and Finland had faced severe problems priory to the Norwegian acquisition make the situation even more dire. It shows that political processes might be ignorant to the facts on the ground. As the old proverb states:
Wise men learn from other mens mistakes, fools from their own.
The timeline (below) tell a story about a classical waterfall approach where potential issues are pushed to the end of the project, to first use when the cost of change is at its highest.
2015 – pre-project started
2017 – acquisition project started
2019 – contract signed with Epic Systems after tendering
2020 – lab module implemented but postponed due to Covid-19 pandemic
2021 – municipalities joining after political decisions
2022 – first use set to April, problems materialise
2023 – problems continue
The project stand out as a schoolbook example of how to fail, leading to the question what could have been done differently? Firstly, capture the essence of the problem in a context map (figure 2) and develop a firm problem statement. Secondly develop alternative options and assess them. Finally, choose the best option, typically the one that is least intrusive and risky to implement.
Figure 2: Context map
Assessment
Given that electronic health care records has been used for decades, all parties have working solutions today. The problem on the table is to create a EPJ that is shared across all parties. Such EPJ can be achieved in two principal ways.
Acquire a new integrated system and enforce it on all parties
Isolate the shared EPJ and integrate applications using API’s
Helseplattformen opted for alternative #1 by choosing an integrated solution from a vendor. Alternative #2 can be realised in two principle ways. By using a federated model according to the EU Data Spaces approach, or by using a centralised model according to the library model. Alternative #1 is tightly coupled and intrusive. Alternative #2 is loosely coupled and nonintrusive.
It is understandable that an integrated system from one vendor looks tempting for decision makers. From 35000 feet Epic Systems with a 78% US market share feels as a safe bet, but transporting a product made in one operational context to a complete new context driven by a complete different vision is most often a painful exercise. The only available approach to dig out the differences between is by paid up-front testing and evaluation of the product before any decision is made.
Products
Products, commercial or open-source is the key to cost efficient realisation of enterprise information systems. Products come in three forms. Large scale integrated products as Epic Systems and SAP. End user productivity tools such as MS Office and Google Docs, and technical components, libraries that are used by developers, they being in the enterprise or in the product space.
The crux with any product is the context that created them in the first place. A product developed for a specific context might be very hard to transport to a similar context in a new market. The larger and complex the product is, the worse it becomes. Therefore the only practical approach is to test before any decision is made. This is time consuming and expensive, but there are no short cuts when dealing with the complexity of mission critical enterprise information systems.
Conclusion
Politics rule information system acquisition processes and the only way to balance out political ambitions with operational excellence is systems architecting. Helseplattformen shows that enterprises need to strengthen their information technology system architecting capability and make it part of their business strategy function. As digitalisation become more and more important the need for digital savvy board members become evident.
Enterprise architects must move out of IT and start serving the business. To do so the enterprise architects must develop design skills and master richer modelling tools and approaches as described in my previous blog post on Object-Oriented Enterprise Architecting and in the next post titled on the essence of system design. It also mean to to work the political and technical realms equally.
An to help us remember why up-front systems architecting is important, lets quote Plato, 400BC.
Object-orientation a.k.a object-oriented thinking / modelling / programming is a way to explore real world complexity by turning real world elements into interacting “objects”. A restaurant, as an example can be modelled as a set of interacting objects representing concepts such as guests, tables, waiters, cooks, orders, bills, dishes, payments and so on. Object-oriented modelling can be conducted by rudimentary tools as as illustrated in figure 1.
Figure 1: Object Model
Object-orientation goes back to the late 1950ties, but was first made available for broader usage with the Simula programming language in the mid 1960ties. Simula inspired new object oriented languages such as Smaltalk, C++, Java and many more.
Object-oriented programming lead to the development of object-oriented analysis and design, and more formal and powerful modelling techniques and languages such as UML (Unified Modelling Language), SYSML, ArchiMate and AKM (Active Knowledge Modelling) to mention a few. It can also be argued that EventStorming, a collaborative workshop technique is object oriented.
On the dark side, object-orientation does not protect agains poor practice. Poor design practice leads typically to tightly coupled systems, systems that become expensive or even impossible to adapt and enhance as technology and business change.
Design Patterns
Design patterns is one way to enhance design practice by provision of tangible abstractions and concepts that help practitioners to create more healthy structures. Patterns originate from civil architecture and is attributed to Christopher Alexander and his work on pattern languages for buildings and cities.
The Gang of Four (GoF) 1995 book Design Patterns – Elements of Reusable Object-Oriented Software was the first book that introduced patterns for object-oriented software development. The book is still relevant and highly recommended as an introduction to patterns.
Another seminal book that embrace patterns is Eric Evans 2003 book Domain-Driven Design: Tackling Complexity in the Heart of Software. Eric argues that business problems are inherently complex, ambiguous and often wicked, and therefor must the development team spend more time on exploring domain concepts, and to express and test them in running code as fast as possible to learn.
Eric argues also for the importance of a common language in the team, theubiquitous language, a language that embraces both domain and technical concepts. OrderRepository is an example of such language that make equally sense for subject matter experts and developers alike. It enables conversations like: orders are stored in the order repository and the order repository provides a function for creating and finding orders.
EventStorming is framed around the discovery and capture of three design patterns: Commands, DomainEvents and Aggregates as illustrated by figure 2.
Figure 2: Event Storming Artefacts
The model reads that the doctor diagnoses the patient and add the diagnosis to the patient record. Then a treatment is prescribed, before the effects are checked at a later stage. EventStorming begins with capturing the capturing the events, and from them the commands and aggregates are derived.
There are particularly three software design patterns that I think should be part of every enterprise architects toolbox.
Command Query Responsibility Segregation (CQRS) separates read operations from write operations enabling a clearer thinking on what those things mean in our architecture. Data Mesh is not possible without CQRS.
Data Mesh is an architectural approach to manage operational and analytical data as products. Its enabled by CQRS and it comes with its own suppleness.
Event Sourcing is based on storing changes as independent events. Bank accounts works this way as each deposit and withdrawal are stored as a a sequence of events, enabling the account to answer what was my deposits on a particular date back in time. Event Sourcing should not be conflated with Event Storming which is a workshop methodology.
The motivation behind the claim is that these patterns shape the architecture and the architects thinking. By knowing them the architect can make rational judgments with respect to their relevance in a given context.
Enterprise Architecting
Enterprise architects have used object-oriented concepts for years taking advantage of modelling languages such as UML, ArchiMate and others. Architects with interest and understanding of agile methodologies might also have explored EventStorming workshop techniques.
Independent of technical tooling enterprise architects face a growing challenge as enterprises digitalise their operating and business models. Take our healthcare model and scale it to a hospital or include multiple hospitals, the primary health services and elder care. In such environment you will have solutions from multiple vendors, solutions from different technical generations, and solutions that are outside your own control. Add then that sector is political sensitive and full of conflicting interests.
The catch being that this is not unique for healthcare but is the nature of the real world. Real world business problems are most often wicked or complex. Scaling up forces architects to slice the problem space into useful modules that can be managed independently. Such slicing must be done with care as coupling and lack of cohesion will haunt the chosen architecture.
The architectural crux is to get the slicing right. Sometimes this is easy as system boundaries follows natural boundaries in the domain. But this is not always the case as many enterprises have ended up with dysfunctional structures that leads to fragile and error prone handovers. Handover of patient information in the healthcare sector is a good example. The catch is that handovers are everywhere and its effects are loss of critical information and rework.
Strategic Design
Domain Driven Design offers a technique that help us model the slicing of a large model called Bounded Context and Context Mapping. Applied on our healthcare example we can create something like the diagram in figure 3.
Figure 3: Context map
Bounded Context are organised into a Context Map that captures the relationships between various bounded context. Adding to the complexity, each bounded context might need access to different aspects of the patient record. Example, pharmacies have no need for individual food constraints that are relevant for nursing homes and hospitals.
Making this even complex is the fact that all these contexts can be further decomposed as in figure 4. Add to this that in the case of an individual patient, specialists from different contexts need to collaborate to decide upon the path forward. It’s normal for surgeons, radiologists and oncologists to discuss a x-ray image of a tumor. Such trans-discipline collaboration is critical for problem solving, and its in these interactions balanced solutions to hard problems are shaped.
Figure 4: Domain decomposition
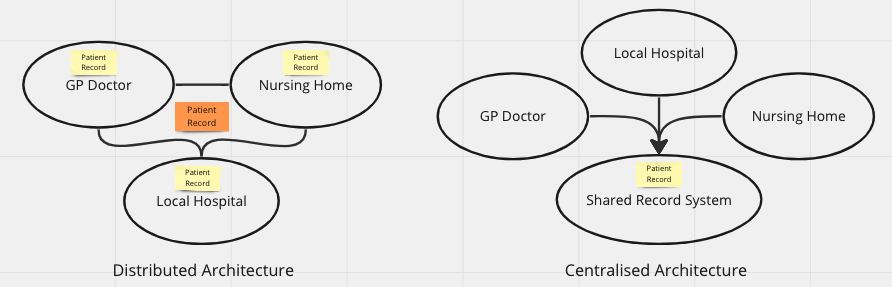
Figure 5 present two architectural alternatives, distributed and centralised. In the distributed architecture each bounded contexts is free to have whatever system they find useful as long as they are able to send and receive patient record update messages (events).
In the centralised architecture a new shared bounded context that manages the patient record has been introduced and the “operational” contexts accesses the shared and centralised record management system. Which one of those alternatives are “best” boils down to tradeoffs. Both come with strengths and weaknesses.
Figure 5: Architectural Styles
What matters is how we choose to pursue implementation. The crux i distributed architectures boils down to message standardisation and the establishment of a transport mechanisms. Centralised architecture can be realised in two principle ways.
By using an old school integrated application with user interfaces and a shared database. Then force everybody to use the same solution. Integrated means tight coupling of user interfaces and the underpinning data / domain model into something that is deployed as one chunk.
By developing a loosely coupled application or platform based on API’s that can be adapted to changing needs. Loos coupling means that the data management part – the record keeping is separated from end user tools along the lines described here.
Making the wrong choice here is most likely catastrophic, but beaware that all alternatives comes with strengths and weaknesses. To understand the alternatives feasibility a bottom-up tactical architecting endeavour is needed. Such endeavour should take advantage of battle proven patterns and design heuristics. In the end a claims based SWOT (Strengths, Weaknesses, Opportunities and Threats) analysis might prove its weight in gold.
Tactical Design
Tactical design implies to dig into what users do, what information they need for doing what they do and to develop the information backbone that shapes the sector’s body of knowledge. Evaluation of implementation alternatives require tactical level design models as the devil is in the details.
Tactical design is best explained using a practical example taking advantage of the capabilities provided by the AKM (Active Knowledge Management ) modelling approach. What make AKM different from other methods and tools is its dynamic meta models. The example model in figure 6 exploits the IRTV (Information, Roles, Tasks and Views) meta model. A deep dive in AKM modelling and meta-modelling will be addressed later.
The example builds on our healthcare case, and the purpose is to highlight the main modelling constructs, their usage and their contribution to the model as a tool for enlightened discussions, and future tradeoff analysis.
Healthcare can be thought of as stories about patients, diseases and treatments and that is what we will try to demonstrate by our toy model. Take note of the fact that some Information datatypes and Views have suggested types that can be used to create a richer and more domain specific language.
Be aware that diseases might have multiple treatments, and that a treatment can be applicable for more than one disease. This is by the way a good example of the “muddiness” of the real world where everything one way or the other is entangled.
Figure 6: AKM Enterprise Architecture Model
The model in figure 6 captures two stories. The first story present a patient consultation session where the GP diagnoses a patient and updates the patient’s medical record. The second story shows how a researcher updates the treatment protocol.
At this point the sharp-eyed should be able to discover a pattern, and for those who don’t please read Reinventing the Library before you start studying figure 7 below. Here the model from figure 6 is restructured and simplified so the key points can be highlighted.
Figure 7: Simplified Enterprise Architecture with Bounded Contexts
Firstly, the sector’s body of knowledge is structured around three concepts that are managed in a “library”. Such library could of cause be extended to include infrastructure components such as hospitals, caring homes, and even staffing. It all depends on what questions the enterprise want to answer and accumulate knowledge about.
Secondly, the design of functional domains by grouping related tasks into what DDD defines as bounded contexts. This design task should be guided by the key design heuristic; maximise cohesion, minimise coupling while reflecting over what can be turned into independent deployable’s if the architecture should take physical form as software applications.
Lastly, views as the key to loose coupling and as artefacts that need to be rigorously designed. Views are the providers of what AKM call workspaces. The model above contain two types of views. The first type is used to separate roles from tasks within a bounded context. This view is typically visual and interactive in nature as its designed to support humans. For those familiar with multi-agent design such view could be seen as an agents environment as explained here.
The second type of view are those that bridges between cohesive functional domains and the underpinning library. These views can also be used to create interaction between operational bounded contexts as can be seen in the case of the Diseases View in figure 7.
View would benefit from being designed according to the CQRS pattern, basically separating commands from Queries as shown in figure 8. In addition to queries and commands can views be the home for transformation, event processing and communication. In a software context views exposes domain specific API’s, they represents bounded contexts and they can be deployed independently as architectural quanta’s. Again the sharp-eyed should see that views might be the key for those who want to think in terms of data mesh and data products. A data-mesh boils down to transforming data so the data can be served to fit the consumers needs.
Figure 8: View Architecture
For those of you who are still here a couple of words about knowledge and the theoretical framework that motivated this post – constructor theory.
Constructor theory
Constructor theory or the science of can and can’t is a rather new theory in theoretical physics developed by David Deutch and later Chiara Marletto at the University of Oxford. The essence of constructor theory is that physical laws can be extended to cover what transformations are possible or not. This implies that Physics can be used to define concepts such as information and knowledge.
A constructor is a “machine” that can perform transformations in a repetitive way and to do that transformation it needs a “recipe”. A factory that create airplanes or cars are examples of constructors. Its the institutionalised knowledge in those entities that make it possible to mass produce samples over time with quality.
If we now revisit figure 7 and 8 it should be obvious that what we have architected could be understood as constructors. An that should not come as a surprise since constructor theory defines information by using two counterfactuals; the possibility of copying and of flipping (change state). Knowledge is defined as self preserving information.
My advice to enterprise architects is to read The science of can and can’t – enjoy as it is the perfect vacation companion.
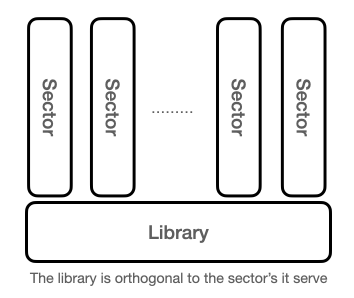
Humans have collected, classified, copied, translated, and shared information about transactions and environment since we saw the first light of day. We even invented a function to perform this important task, the library, with the library of Alexandria as one of the most prominent examples from ancient time.
The implementation of the library has changed as a function of technological development while maintaining a stable architecture. The library is orthogonal to the society or enterprise it serve as illustrated in the figure below.
The architectural stability can most likely be explained by the laws of physics. David Deutsch published in 2012 what is now called constructor theory that use contrafactual’s to define what transformations are possible and not. According to the constructor theory of information can a physical system carry information if the system can be set to any of at least two states (flip operation) and that each state can be copied.
This is exactly what the ancient libraries did. The library’s state change when new information arrived allowing the information to be copied and shared. The library works equally well for clay tablets, parchments, papyrus rolls, paper, and computer storage. The only thing that change as function of technology is how fast a given transformation can be performed.
With the introduction of computers the role of the library function changed as many functions migrated into what we can call sector specific applications and databases. In many ways we used computers to optimise sectors at the cost of supporting cross sector interoperability. I think there was a strong belief that technology would make the library redundant.
The effect being that cross sector interaction become difficult. The situation has in reality worsened as each sector has fragmented into specialised applications and databases. What was once an enterprise with five lines of business (sectors) might now be 200 specialised applications with very limited interoperability. This is what we can call reductionism on steroids as illustrated in the figure below.
The only companies who have benefitted from this development are those who provide application integration technology and services. The fragmentation was countered by what I like to call the integrated mastodonts that grew out from what once was a simple database that has been extended to cover new needs. Those might deserve their own blogpost and we leave them for now.
Data platforms
In the mid 1990ties the Internet business boom began. Amzon.com changed retail and Google changed search as two examples. A decade later AWS provided data center services on demand, Facebook and social media was born, and in 2007 Apple launched the iPhone, changing computing and telephony forever.
Another decade down the road, around 2015, the digitalisation wave reached the heavy-industry enterprise space. One of the early insights was the importance of data and the value of making data available outside existing application silos. Silos that had haunted the enterprise IT landscape for decades. By taking advantage of the Internet technology serving big data and social media application the industrial data platform was born.
The data platform made it easier to create new applications by liberating data traditionally stored in existing application silos as illustrated below. The sharp minded should now see that what really took place was reinventing the library as a first order citizen in the digital cityscape.
The OSDU™ Data Platform initiative was born on the basis of this development where one key driver was the understanding that a data platform for an industry must be standardised and its development require industry wide collaboration.
Data platform generations
We tend to look at technology evolution as a linear process, but that is seldom the case. Most often the result of evolution can be seen as technological generations, where new generations come into being while the older generations still are in existence. This is also the case when it comes to data platforms.
Applied on data platforms the following story can be told:
First generation data plattforms followed the data lake pattern. Here application data was denormalised and stored in an immutable data lake enabling mining and big data operations.
Second generation data plattforms follows the data mesh pattern taking advantage of managing data as products by adding governance.
Third generation data platforms take advantage of both data lake and data mesh mechanisms but what make them different is their support of master data enabled product lifecycle management.
Master data is defined by the DAMA Data Management Body of Knowledge as the entities that provide context for business transactions. The most known examples includes customers, products and the various elements that defines a business or domain.
Product lifecycle management models
Master data lifecycle management implies capturing how master data entities evolve with time as the their counterparts in the real world change. To do so a product model is required. The difference between a master data catalogue and a product model is subtle but essential.
A master data catalogue contextualise data with the help of metadata. A product model can also do that, but in addition it captures the critical relationships in the product structure as a whole and tracks how the product structure evolve with time. Using the upstream oil and gas model below the following tale can be told.
When a target (pocket with hydrocarbons) shall be realised a new wellbore must be made. When there are no constraints there can be thousand possible realisations. As the number of constraints are tightened the number of options are reduced and in the end the team land on one that is preferred, while keeping the best options in stock in case something unforeseen happens. Let’s say that the selected well slot breaks and can’t be used before it is repaired, a task that take 6 months. Then its possible for the team to go back to the product model and look for alternatives.
Another product model property is that we can go back in time and look at how the world looked like at a given day. In the early days of a field its possible to see that there was an area where we had seismic that looked so promising that exploration wells was drilled, leading to the reservoir that was developed and so on. The product model is a time machine.
Our example product model above is based on master data entities from upstream oil and gas, entities that are partly addressed by the OSDU™ Data Platform. There are two reasons for using the OSDU™ Data Platform as an example.
Firstly, I work with its development and have reasonably good understanding of the upstream oil and gas industry. Secondly, the OSDU™ Data Platform is the closest I have seen that can evolve into a product lifecycle centric system. The required changes are more about how we think as we have the Lego bricks in place.
Think of the OSDU™ Data Platform as a library of evolutionary managed product models, not as only a data catalogue. Adapt the DDMS (Domain Data Management Services) to become work spaces that operates on selected aspects of the product models, not only the data. The resulting architecture is illustrated below.
Moving to other sectors the same approach is applicable. A product model could could be organised around patients, deceases and treatments or retail stores and assortments for that matter. The crux is to make the defining masters of your industry the backbone of the evolutionary product model.
This story will be continued in a follow-up where the more subtle aspects will be explored. One thing that stand out is that this make it easier to apply Domain Driven Design patterns as the library is a living model, not only static data items.
Hopefully if you have reached to this sentence, you have some new ideas to pursue.
From time to time struggling information technology (IT) projects reaches the news. I have during my career observed and been part of both successful and failed projects. Despite that its quite clear what is required to succeed, organisations repeats the same mistakes again and again and learning across sectors seams impossible. For more theoretical background please read the previous posts on digitalisation and change management.
Success or failure depends on three things:
Appropriate acquisition approach, buy when you can, build when the problem domain is wicked
Fit for purpose interaction and domain models is paramount
Choosing the right acquisition approach for the problem domain at hand
Buy vs build is not a black and white discussion as a build strategy will depends on many commercial components, they being open sourced licensed or commercial. It’s much more about who is the system integrator that matters. But as all of us who have played with Lego knows, small bricks are more flexible than the big ones. That applies for software systems too.
Of these the nature of the interaction model is the most important. To what degree does the digital information system serve the human users in fulfilling their objectives and task? Alternatively how much must the human users adapt their behaviour to suit the digital information systems needs.
My conclusion is that if IT projects was lead and organised according to their true nature a lot of painful problems could have been avoided. Would that made them cheaper? Not necessarily, but we would have had something that was useful when the money was spent.
Models
Digital information systems are models of the domain’s they serve, and as for all models they only captures the original development team’s understanding of that domain. Information systems come with two models.
The internal domain model capturing the concepts of the domain. That being about patients, diagnosis and treatment’s, or wellbore’s, geological markers and drilling strings, or customers, stores and assortments to mention three examples.
The interaction model defining how the individual users interacts with the information systems. Can data be entered from a smart phone app or is a full blown PC required. How many clicks and movements are needed to complete a task is part of this model.
In some systems the interaction model is just a view of the internal model, exposing the end user for all the complexity of the domain at hand, in others there are clear separation of the two. Public transport applications are examples of the latter. They provide you as a traveler with an easy to use interface for buying a ticket without exposing you for how to schedule the fleet of busses and trains.
The more diversity and wickedness of the domain, the more complex the information system domain models become. Enterprise systems covers multiple domains making the model integration a key concern. Using a patient record system as an example. Management of blood tests, x-ray images and treatments are all domains in their own that take different form dependent of function and role.
Understanding whether a model is fit for purpose or not is paramount.
Models are just models, what is a good model for one task might be useless for another. Take the London underground map as an example. Its useless for a streets of London walkabout.
Architecture
The architecture of digital information systems defines how the system is structured including the technology used. The software industry has operated with several architectural styles over the years, all of them coming with strengths and weaknesses. Which one is the “best” for a given problem requires a trade-off analysis. To learn more, please read this book.
Information systems that are built as integrated applications also known as monoliths works fine if the problem domain is monolithic. An integrated enterprise might be well served by this kind of architecture. In the case the problem domain is distributed and consists of actors that operate with large degree of independence a more loosely coupled or even distributed architecture might be better.
Choosing a fit for purpose architecture is crucial and is most likely the place where most mistakes are made.
One architectural pattern that looks promising is to separate data from applications. How and why this has been done with success can be studied in my post on the OSDU™ Data Platform. The pattern will be addressed in a future post as well.
Observations
Successes
When analysing successes the following elements stick out:
Well defined problems, many of them related to scientific / technical computing
Highly competent teams and most often not to large
Freedom to use and even develop state of the art technology
Clear expectations and hard deadlines
Leaders who understand the name of the game and facilitate and pave way
Agile and adaptive delivery processes
Fit for purpose architecture
Serves human users to succeed in fulfilling their objectives and tasks
When the problem domain is clear and ordered a lot gets easier. Sometimes hard deadlines can help as was the case for the work I did for the Norwegian Police up to the Olympics in 1994. The required software had to work on a particular day. And so it did even parts of it was in a “respirator”.
Failures
When analysing failures the following elements stick out:
Ill-structured and wicked domains, many of the related to vaguely articulated business problems
Many opinionated stakeholders that need to be pleased
Technologically constrained, i.e., forced to use outdated technology or vendor provided solutions
Unclear expectations and scope
Incompetent leaders and teams
Unfit for purpose architecture
Technology driven
Enforces a nonintuitive interaction model on the human users tapping them for energy
Attaching ill-structured, wicked and even complex problem domains as they are ordered is probably the worst thing to do. Stakeholder diversity is a contributor to the wickedness and I will argue the more political sensitive the domain is the worse it become.
Build or make
What type of acquisition process is most appropriate is a key question. What is the best approach depends on the problem domain and the level of commoditisation of the domain. If you need a new text editor pick one of the many that exists, you can even pick different ones dependent on what you are writing. As an example, this text is produced with the WordPress editor.
In the other end of the spectrum you find national information systems for tax and benefit calculations. These information systems are governed by national laws and might change on a yearly basis due to political priorities. This is a domain that require a build approach. Choosing a build approach does not mean that everything has to be built, but that the system owner is responsible for a as healthy and cost efficient system as possible within available technological frameworks.
The less commoditised, the more ill-structured and wicked the more a build approach fits the nature of the problem space. The risk rises exponential when enterprises chooses a buy approach on what is a complex and evolving problem domain.
Choosing the appropriate acquisition approach is the difference of success and failure.
Failing here and what you are left with is the projects obituary. Then said thing thou is that too many projects belief in a buy approach because the inherent complexities in the domain and the interplays are underestimated.
Change management is used as a collective term for all approaches to prepare, support, and help individuals, teams and organisations to change. I was challenged by a colleague to put forward my thoughts after she had read my previous post on digitalisation as a complex undertaking.
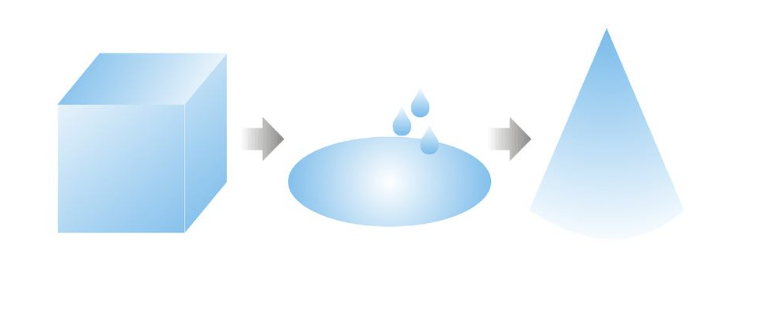
Change implies that something go from one state to another as water during its phase shifts from ice to floating to gas. Change management boils down to the management of the phase shifts, the transitions, the in between’s than the end states. How difficult this can be can be tested at home by boiling milk. Be prepared to clean up or pay attention to what takes place in the kettle.
The history of change management goes back to Kurt Lewin‘s work on group dynamics and change processes in the first half of the 20th century. At the time of his death in 1947, Lewin was seen as on of the foremost psychologist’s of his day. Today is Lewin best known for his three step change-model, also known as the unfreeze-change-refreeze using using an ice block as metaphor (fig. 1).
Fig 1. Lewin’s Unfreeze-Change-Refreeze model
The challenge with this model is that enterprises pay to much attention on the as-is and the to-be, while ignoring that success or failure is down to the nature of the phase shifts themselves. How this take place is best illustrated by the anatomy of a typical enterprise change process:
A problem or assumed short coming has been identified and the board of directors establish a project that is tasked to find solutions and propose alternative course(s) of actions.
The board of directors decides to implement one of the proposed solutions and kicks off an implementation project tasked to implement the recommended changes.
The implementation project create new organisational units, move people around while people do as best they can to make the wheels turn around.
I know I am tabloid here, but the most important takeaway is that such plan driven approaches does not work. The documentation is overwhelming, and still enterprises stick to the practice. What has proved to work are initiatives founded on lean and agile principles, principles that take into account that the challenge is the transition, not the end states.
Timing change
One reason old practices stick for to long can be found in Clayton Christensen work on disruptive innovation and product lifecycles where a product follows overlapping S-curves. Enterprises with profitable products are almost resilient to change. How Apple’s iPhone knocked Nokia out of business is one good example. Same is how the minicomputer industry was eradicated by the micro-processor in 1989-91. What was perceived as a healthy industry was gone in 18 months.
Dave Snowden has taken this understanding to a new level with his flexuous curves and the liminal moment (the yellow zone in figure 2) that marks the opportunity window. It shows that the change window is when your product is dominating. This is also a reason why changing is so hard.
Fig 2: Credit to Dave Snowden and the The Cynefin Company
Many enterprises stick to old practice despite that the evidence for change is overwhelming. This does not stop with products, but is applicable to work practices as well.
Leading change is hard
Disruptive innovation and flexuous curves can help us to better understand why and when change might be favourable, but they offer no help when it come to leading change efforts. Carl von Clausewitz might be one of the first who put words on the hardship of change in context of a complex system in his seminal 1832 book On War where he state:
“Everything is simple in war, but the simplest thing is difficult. These difficulties accumulate and produce a friction, which no man can imagine exactly who has not seen war.”
War, or battle to use a word that is more representative of 19th century reality can be understood as the dynamic state transition from pre-battle to post-battle that consists of timed and coordinated movements and counter movements of competing agents (armies). The competition ends when one or both sides have had enough. Each force being a interlinked hierarchical network of units built from individual agents and equipment.
There are two main takeaways from the war analogy.
That business and change processes can be understood as timed and coordinated movements of resources and therefore face “friction”. Today we would not talk so much about friction but that businesses and enterprises are examples of complex systems.
That the Prussian general staff under the command of General Helmuth von Moltke developed a new leadership style called mission command that is still used, a leadership style that emphasis subordinates to make decisions based on local circumstance in their strive for fulfilling the superiors intent. Stephen Bungay explains how these principles are relevant and can be repurposed for business in his book The art of Action.
To conclude, leading change processes is hard because they come with friction (things does not work out in practice as planned) and need a different leadership style than bureaucratic top down linear plans to succeed. This also challenge the way leaders are identified and trained.
An individuals leadership practice is an emerging property that is shaped by the context, and therefore can’t be copied. This breaks with the idea that a good leader can lead anything. This mean that its most likely different personalities that succeeds in operational contexts versus say a product development context. As individuals climb the corporate leadership stair this become crucial. To put an individual who have excelled in one context believing that he/she will succeed in a completely different context is dangerous.
How to succeed with change
The literature is crystal clear on how to succeed with change processes. Initiatives that empower individuals to drive change as activists, initiatives where individuals are invited to contribute, and initiatives that move from managed to organic has the best probability to succeed.
To move from managed to organic is most likely the most important of the three. Kurt Lewin’s three step change model still guides how leaders think about change, the problem being that there is no room to be frozen any more. According to McKinsey we need permanent slush that enables constant experimentation with new operating models, business models and management models, adopting the practices required when dealing with complex systems.
A complex system has no linear relationships between causes and effects and can’t be managed by linear measures. This leaves us with three principles as pointed out here:
Initiating and monitoring micro-nudges, lots of small projects rather than one big project so that success and failure are both (non-ironically) opportunities
Understanding where we are, and starting journeys with a sense of direction rather than abstract goals
Understanding, and working with propensities and dispositions, managing both so that the things you desire have a lower energy cost than the things you don’t
Be also aware that its the alternatives with lowest energy cost that will win in the long run. Thats the reason point #3 is so important. We need to make what we will like to see more off cheaper than what we will like to see less off. These things must be anchored in the stories or narratives told by those who experience the existing reality and who in the end owns and lives with the changes.
Summing up, literature is crystal clear on what is the best way to approach change process. It boils down to knowing where you are, move in small steps and maintain a direction. Given the facts, why do enterprises stick to their old failed practices. To answer that question we must address some of the counter forces in play.
Counter forces
Counter forces come in many facets.
Old habits are hard to change, as everybody knows who have tried to change a undesired behaviour. Enterprises are structures with internal friction and change resistance that take many forms. Not invented here might be one. Short term energy expenditure might be another.
Lewin’s original model is linear, easy to grasp and leave senior leadership with the illusion that change is a final game that can be managed top down. I personally think it feels better from an ego’s point of view as well. Last but not least, its an easier sell for management consultancies providing case studies and best practice.
Procurement processes. Many change processes related to introducing new digital capabilities involves procurement of new technology. Procurement processes require that you know what you need. One thing is to buy 100 car’s or 5000 meter with drill pipes. Digitalising a business process something completely different.
Perceived senior management risk. Executives seek ways to reduce the perceived risk. One such way is to have contract. In the 1980ties nobody was fired for having signed on with IBM. My theory is that this boils down to psychology. Late sports psychology professor Willy Railo stated back in the 1980ties that “you don’t dare to win if you don’t dare to loose”. In other words its the fear of failure that trigger the behaviour that leads to failure.
Approaching business as a finite game. Business and change processes are infinite games, but due to various factors leaders behave as their finite. A finite game is a game with fixed rules and time (football). An infinite game is a game that never ends and enterprises that acknowledge that their in it for the long run will benefit. To learn more check out this link. The main problem might be that funding might be finite as in the case of public sector initiatives that are run by budget allocation.
As we can read, there are many factors and counter forces in play. Some of these are most likely unconscious such as fear, others boils down to ignorance and laziness.
Synthesis
Change management has been with us for a while and literature is clear on what it take to succeed with change. Experiments, involvement, empowerment, small steps, continuous adjustments based on feedback and so om.
Despite this many enterprises stick to plan based approaches with failure in the end. There are many forces that leads to this, one being the finite nature of budgets, and particularly budgets that are managed by political processes.
To me this is at the stage where we know what to do, so its just go do it in ways we know work. Adapt agile practice and begin navigate the maze.
Two recommended readings are the EU field guide on crisis management and this article on Safety Interventions in an energy company. Teaser provided from it’s abstract
The paper describes a case study carried out in an electric utility organization to address safety issues. The organization experiences a less than satisfactory safety performance record despite nurturing a culture oriented to incident prevention. The theoretical basis of the intervention lies in naturalistic sense-making and draws primarily on insights from the cognitive sciences and the science of complex adaptive systems. Data collection was carried out through stories as told by the field workers. Stories are a preferred method compared to conventional questionnaires or surveys because they allow a richer description of complex issues and eliminate the interviewer‟s bias hidden behind explicit questions.
The analysis identified several issues that were then classified into different domains (Simple, Complicated, Complex, Chaotic) as defined by a Sense-Making framework approach. The approach enables Management to rationalize its return on investments in safety. In particular, the intervention helps to explain why some implemented safety solutions emanating from a near-miss or an accident investigation can produce a counterproductive impact. Lastly, the paper suggests how issues must be resolved differently according to the domain they belong to.
Complexity is the result from something with many parts that interact in multiple ways, following local rules that lead to nonlinearity, randomness, collective dynamics, and emergence. Emergence represents the concept of being more than its parts, its unpredictable properties or behaviours created by the many interactions.
Human societies is one example of a complex entity or system. Both the Chinese Covid-19 protests and the 2022 Iranian turmoils are examples of how emergence can materialise from a state that at outset looks calm or stable.
Other examples of complex systems are traffic and traffic control, Earth’s climate and biological eco-systems, warfare, and firefighting. Of these traffic and traffic control are man made where safe and secure behaviour is maintained through simple rules. Earth’s climate is a different beast with its unknown and even unknowable relationships.
Digitalisation
What is less understood is that digitalisation is a complex undertaking. Digitalisation boils down to retrofitting human enterprises with new digital tools, tools made from computer software, tools enabling change of business and operating models.
There are several factors that contribute to the inherent complexity.
Firstly, digitalisation impacts the interactions in human organisations that are complex systems before the technology arrived on the scene.
Secondly, computer software captures and materialise human ideas and thoughts with the caveat that its impossible to predict the effect of an idea before its tested. The effect being that digital tools are shaped by their creation process and context.
Finally, the fallacy that buying a off the shelf solution makes the organisational implementation or retrofitting easy.
All digitalisation initiatives begin with a promise that the new technology / solution and new ways of working will be for the better. In most cases the opposite is true, most often large scale digitalisation efforts goes wrong or at least run into severe problems.
“Helseplattformen“, a Norwegian health care digitalisation effort that has ended up in the news lately due to problems. The scope is a new integrated patient record system across multiple hospitals, specialists and GP’s in one of Norway’a health regions. According to the news from January 2023 3.8 billion NOK’s have been spent and its expected that additional 900 million NOK is needed (who belive in that?). One thing is the costs, more important is the impact on the daily health service production for 720.000 inhabitants.
This is just one example out of many. I have personally witnessed several dosens failed digital or IT related initiatives during my career, leaving us with why. Why do these undertakings run into trouble and why are we not able to learn?
The simple answer is that digitalisation is a complex undertaking as enterprises are complex adaptive systems with non-linear and unpredictable cause-effect relationships. To explore what that mean in practice is it time to turn to Dave Snowden and his Cynefin sense making framework.
Cynefin
Cynefin, pronounced kuh-nev-in, is a Welsh word that signifies the multiple, intertwined factors in our environment and our experience that influence us (how we think, interpret and act) in ways we can never fully understand.
Cynefin domains
Cynefin divides the world in two, the ordered world to the right and the disordered world to the left each world divided into two domains separated by a liminal zone. In the clear domain there is a direct response from what is sensed and an appropriate response and the domain is governed by best practice. When best practice fails, we fall off the cliff into chaos. In the complicated domain the relationship between what is sensed and the appropriate response require analysis and expert judgment. There can be more than one solution to a problem and it requires good practice.
In the disordered world we find the complex domain and chaos. In the complex domain there is no linear relationship between what can be sensed and the appropriate response. The only way to deal with the complex domain is to probe, then sense and finally figure out what to do. This is the domain of experimentation and its a domain that require exaptive (repurposing / innovative) practice. We discover that something we have can be used to solve something we never had thought about.
At the bottom we find the chaotic domain where the only way forward is to act, then sense and respond. When in chaos practice is made as we go.
The liminal zone is split in two; A – aporetic and C – confused. Being confused in context of Cynefin implies not knowing what domain we are in and therefore we end up using the wrong approach to the problem at hand. Addressing a clear problem as it was a complex problem by running experiments is not effective. The opposite is worse, addressing a problem in the complex domain as it was clear or complicate leads easily into chaos.
Being in the aporetic zone we know we deal with unknowns and even unknowables and choose to use that insight to our advantage by running parallel experiments. This is what agile software methods like Scrum do and it goes even further. Hackathons are structured visits to chaos where we do stuff and figures out what we learnt when finished.
By accepting that digitalisation is a complex undertaking that requires enabling constraints, exaptive (repurposing) practice and a probe-sense-respond approach is the key to success. We must stop approaching digitalisation as it is in the ordered world using linear processes and thinking.
Enterprise practice
Enterprises, they be in private and public sector trives in the ordered world. The beliefs in “ordung must sein” can be overwhelming. There are routines and processes for everything. That said, there are thousands of things that need to be done within an enterprise that fall into the clear and complicated domains.
Problems pile up when topics belonging to complex domain is approached and managed as it is complicated or clear. Digitalisation and software development are two such things. Some enterprises uses task forces when something serious have gone wrong. This is a wise thing to do when you have felt over the cliff into chaos and need to find a way back to order, but its reactive in nature and it will never prevent them from falling over the cliff next time.
The catch is that when a complex problem fails, the path toward chaos is linear. What and why it went wrong can be explained, but it can’t be prevented without deep change to the culture and governance model.
Enterprises must train their leaders and employees to work experimentally with digitalisation and improvement. Admiral Nimitz understood this 80 years ago, it should be within reach for todays enterprise leaders as well.
Enjoy the story and embrace complexity. Its a wonderful world of opportunities.
Nimitz
When the US Navy entered WWII in 1941 it was equipped with two new technologies, radar, and VHF radio. Technologies that were expected to enable better understanding of the battlefield and clarity in the decision making. It was the opposite that happened. The new technology contributed to confusion and disaster.
Admiral Nimitz and his staff understood that something had to be done and decided that each ship should have a new function, a Combat Information Center (CIC). Since once size does not fits all, he decided that each ship should experiment with how to implement the function allowing them to nurture what worked. For more details read the book [link].
The output from the CIC was a plot representing the ships understanding of the battlefield, own and enemy resources from interpretation of radar and radio traffic. There are many things that can be learned from this 80-year-old story. Firstly, that what Nimitz and his staff did was to use exaptive practice, they repurposed plotting that the Navy had used for decades. Secondly, he probed by running parallel experiment governed by enabling constraints e.g., that every ship should have a CIC, while its design was adapted to ship type.
During 1943 as the experimentation continued the CIC evolved from being an information system to becoming a system of distributed cognition. This evolution came from practical combat experience leading to the CIC being tasked to use weapons in given situations. All in all, the CIC both clarified and simplified the work of ship command.
Ultimately the CIC became a system of distributed cognition fully integrated with the ships command functions. The work of making sense of available information was shared across different roles that distributed the cognitive load, and allowed for rapid assessment, analysis, synthesis of incoming information using visual plots as a symbolic information system.
Conclusion
The US Navy’s CIC is an example of how to address a complex challenge using Cynefin’s recommended approaches. Nimitz use of safe-to-fail experiments, exaptive practice and enabling constraints unlocking his subordinate’s creativity enabled new unanticipated solutions to mange shipboard information. Nimitz deliberately avoided imposing solutions and instead created the conditions for a solution to emerge. He provided direction and used regular feedback loops to amplify useful approaches and dampen the less useful ones.
For those in doubt, this is the practice that digitalisation initiatives require.
The OSDU™ Data Platform is the most transformative and disruptive digital initiatives in the energy industry. Never before have competitors, suppliers and customers joined forces to solve a common set of problems taking advantage of open-source software licensing, agile methods and global collaboration.
Originally OSDU was an acronym for Open Subsurface Data Universe, directly derived from Shell’s SDU (Subsurface Data Universe) contribution. There is great video presenting Shell’s story that can be found here. The OSDU™ Forum decided to remove the binding to the subsurface and to register OSDU as trademark owned by The Open Group paving the way for adaptation beyond subsurface, enabling constructs like:
OSDU™ Forum – the legal framework that govern community work
OSDU™ Data Platform – the product created by the forum
The OSDU™ Forum’s mission is to delivers an open-source, standards-based, technology-agnostic data platform for the energy industry that:
stimulates innovation,
industrialises data management, and
reduces time to market for new solutions
The mission is rooted in clearly stated problems related to digitalisation of energy and the journey till today is summarised below:
2016 – 2017
Increased focus on digitalisation, data and new value from data in the oil and gas industry
Oil and gas as companies make digital part of their technology strategies and technical roadmaps
2018-2019:
Shell invites a handful oil and gas companies to join forces to drive the development of an open source, standardised data platform for upstream O&G (the part the find and extract oil and gas from the ground)
The OSDU™ Forum was formally founded in September 2018 as an Open Group Forum based on Shell’s SDU donation as the technical starting point
Independent software companies, tech companies and cloud service providers join. Bringing the cloud service providers onboard was a strategic aim. Without their help commercialisation would become more difficult
July 2019: SLB donates DELFI data services, providing additional boost to the forum.
2020-2021:
Release of the first commercial version – Mercury from a merged code base is made available by the cloud service providers for consumption
2022 and beyond
Operational deployments in O&G companies.
Hardening of operational pipelines and commercial service offerings (backup, bug-fixing)
Continuous development and contribution of new OSDU™ Data Platform capabilities.
The OSDU™ Data Platform was born in the oil and gas industry and it is impossible to explain the drivers without a basic understanding of the industrial challenges that made it, challenges that come from earth science and earth science data.
Earth science
Earth science is the study of planet Earth’s lithosphere (geosphere), biosphere, hydrosphere, atmosphere and their relationships. Earth science forms the core of energy, it be oil and gas, renewables (solar, wind and hydro) and nuclear. Earth science inherently complex because it’s trans-disciplinal, deals with non-linear relationships, contain known unknowns, even unknowable’s, and comes with a huge portion of uncertainty.
Hydrocarbons forms in the upper part of earth’s lithosphere. Dead organic material is transported by rivers to lakes where it sink and is turned into sediments. Under the right conditions the sediments become recoverable hydrocarbons by processes that takes millions of years. In the quest for hydrocarbons geo-scientists develop models of earths interior that help them to predict where to find recoverable hydrocarbon.
Earth models
Earth models sits at the core of the oil and gas industries subsurface workflows and are used to find new resources, develop reservoir drainage strategies, investment plans, optimise production and placement of new wells. Earth models are used to answer questions like:
How large hydrocarbon volumes exists?
How is the volume placed in the reservoir?
How much is recoverable in the shortest possible time?
As reservoirs empties, where are the remaining pockets?
How much has been produced, from when, and how much remains?
How to drain the volumes as cost efficient as possible?
Earth models are developed from seismic, observations (cores, well logs and cuttings) and produced volumes. When exploring new areas access to relevant datasets is an issue. Exploration wells are expensive and finding the best placement is important. Near-field exploration is easier as the geology is better known. Some production fields use passive seismic monitoring allowing continuous monitoring of how the reservoir changes while being drained. Another approach is 4D seismic, where new and old seismic images are compared.
Seismic interpretation means to identify geological features such as horizons and faultsand to place them at the appropriate place in a cube model of the earth. How this is done is shown in this 10 minute introduction video.
The pictures to the left shows a seismic image. To derive useful information requires special training as it is a process of assumptions and human judgement. To the right a picture of log curves and for more information about well logging please read this. Seismic datasets are very large and relatively expensive to compute. Well logs are smaller in size, but they come in huge numbers and choosing the best one for a specific task might be a time consuming process.
Timescales
Oil and gas fields are long-lived and the longevity represents a challenge on its own that is best illustrated using an example. The Norwegian Ekofisk field, discovered in 1969, put on stream in 1971, and expected to produce for another 40 years. The catch being that data acquired with what is regarded state of art technology will outlive the technology. Well logs from the mid sixties, most likely stored on paper are still relevant.
Adding to the problem is the changes in measuring method and tool accuracy. This is seen when it comes to metrological data. Temperature measured with a mercury gauge come with an accuracy of half degree celcius. Compare that with the observed temperature rise of one degree over the last hundred years. Being able to compare apples with apples become critical and therefore is additional sources of data required.
When the storage technology was paper this was one thing, now when we storage has become digital its something else. For the data to be useful a continuous reprocessing and re-packeting is required.
Causal inference
Subsurface work, as other scientific work is based on causal inference i.e., asking and answering questions attempting to figuring out the causal relationships in play.
The Book of Why defines three causation levels seeing, doing and imagination as illustrated by the figure below.
Source: The Book of Why
Seeing implies observing and looking for patterns. This is what an owl do when it hunts a mice, and it is what the computer does when playing the game of Go. The question asked is; what if I see… eluding to that if something is seen it might impact the probability for something else to be true. Seismic interpretation begins here with asking where are the faults while looking at the image.
Doing implies adding change to the world. It begins by asking what will happen if we do this? Intervention ranges higher than association because it involves not just seeing but changing what is. Seeing smoke tells a different story than making smoke. Its not possible to answer questions about interventions with passively collected data, no matter how big the data set or how deep the neural network. One approach to do this is to perform an experiment, observing the responses. Another approach is to build a causal model that captures causal relationships in play. When we drill a new well that can be seen as an experiment where we both gather rung one data, and also discover rung 2 evidence related to what work and what does not work. The occurrence of cavings and a potential hole collapse being one example.
A sufficient strong and accurate causal model can allow us to use rung one (observation) data to answer rung two questions. Mathematically this can be expressed as P(cake | do (coffee)) or in plain text, what will happen to our sales of cake if we change the price of coffee.
Imagination implies asking questions like my headache is gone, but why? Was it the aspirin I took? The food I ate? These kind of questions takes us to counterfactuals, because to answer them we must go back in time, change the history and ask, what would have happened if I had not taken the aspirin? Counterfactuals have a particularly problematic relationship with data because data is by definition facts. Having a causal model that can answer counterfactual questions are immense. Finding out why a blunder occurred allow us to take the right corrective measures in the future. Counterfactuals is how we learn. It should be mentioned that laws of physics can be interpreted as counterfactual assertions such as “had the weight on the spring doubled, its length would have doubled” (Hooke’s law). This statement is backed by a wealth of experimental (rung 2) evidence.
By introducing causation the value of useful data should be clear. Without trustworthy data, that we are not able to agree about what we can see, there cant be any trustworthy predictions, causal reasoning, reflection and action. The value of a data platform is that it helps with the data housekeeping at all levels. Input and output from all the three rungs can be managed as data.
Causal models are made from boxes and arrows as illustrated in the figure below. How the factors contributes can be calculated as probabilities along the arrows. The beauty of causal models is that their structure is stable, while the individual factors contribution will change. Loss mean that mud leaks into the formation due to overpressure, and gain implies that formation fluids leaks into the wellbore. Both situations are undesired as they might lead to sever situations during drilling.
Finally, dynamic earth modells based on fluid dynamics captures causal relationships related to how fluids flow in rock due to the laws of physics.
Digitalisation
Until less than 60 years ago earth models as most other models was paper based. With the development of computers earth models have become digital with raw data and derived knowledge carved into software and databases.
Despite digital tooling earth science work practice has not changed much. Scientists collects data, build models and hypothesis, analyse and predict possible outcomes.
One thing that has changed is the amount of data. The dataset shared by Equinor for the retired Volve field consists of 40.000 files. Volve was a small field producing for a decade. To know what dataset can / should / could be used for what type of work is not trivial.
Another challenge is that each discipline has its own specialist tools emphasising different aspects of the dataset. This mean that two disciplines will struggle to synthesise their results at the end. Adding to the challenge the fact that models are tied to the tool and the individual users preferences and understanding.
The result is an individ centred, discipline specific tooling that make a holistic (trans disciplinary) view difficult if at all possible. Said in other words: we have tools the forest, tools for the threes and tools for the leaves, but no tool that allow us to study threes in context of the forest or leaves in context of a three. Philosophically speaking is this the result of applying reductionism on a complex problem.
The effect is fragmentation and inconsistency across individuals, tools, disciplines and organisational units leading to loss of knowledge, loss of trust and continuously rework as people struggle to build on each others work.
Fragmentation is a good starting point for the next topic that create a lot of pain when building digital data models, the question of what is one thing and when does a thing change so much it become a new thing.
One thing
According to William Kent in Data and Reality answering what is one thing forces us to explore three key concepts:
Oneness. What is one thing?
Sameness. When we say two things are the same, or the same thing? How does change affect identity?
Categories. What is it? In what categories do we perceive the thing to be? What categories fo we acknowledge? How well defined are they?
Oneness underlies the general ambiguity of words and we will use an example from the book regarding the word “well” as used in the files of an oil company.
In their geological database, a “well” is a single hole drilled in the surface of the earth, whether or not it produces oil. In the production database, a “well” is one or more holes covered by one piece of equipment, which has tapped into a pool of oil. The oil company had trouble integrating these databases to support a new application: the correlation of well productivity with geological characteristics.
This imply that the word well is ambiguous across contexts. Observe that the ambiguity lays with the understanding of the concept well. The production database might have used the term well for what a geologist might think of as a wellbore.
What we observe here is ambiguity across contexts. The production database might have used the term well for what a geo-scientist might think of as a wellbore. Reading along we find this:
As analyst and modellers, we face “oneness”, “sameness” and “categories”. Oneness means coming up with a clear and complete explanation of what we are referring to. Sameness means reconciling conflicting views of the same term, including whether changes (and what type of changes ) transform the term into a new term. Categories means assigning the right name to this term and determining whether it is an entity type, relationship, or attribute on a data model. Oneness, Sameness and Categories are tightly intertwined with one another.
The main takeaway from this is that the ambiguities that we find in a trans-disciplinary fields such as earth science will create problems if not properly addressed. These ambiguities has more to do with how disciplines thinks and express themselves than finding a digital representation. The challenge sits with the semantics of language.
The value of standardising terminology is seen in medicine and anatomy where every piece of the human body is given a latin name that is thought and used across disciplines.
Contextualisation
Domain Driven Design provide two architectural patterns; Bounded Context and Context Mapping that help software architects and data modellers to create explicit context and context relationships. Bounded contexts and context maps allows architects to practice divide and conquer without loosing the whole. Reconciling might prove to be much harder than first thought. The picture below shows practical use of how bounded contexts can be applied on the well problem described above.
By modelling the two applications as bounded context it become clear that reconciliation will require use of a new context as forcing one applications definition on the other will not work. Therefore is it better to create a new bounded context that reconcile the differences by introducing new terminology.
The role of a data platform
A data platforms store, manage and serve data to consumers while adhering to the governance rules defined for the data. A data platform is not a database, but it can be build using data base technology. A data platform must also address the problems that come from semantic ambiguity (what is one thing), support the timescales and complexities found in the physical world, and the reality that both the physical world as well as its digital representation change with time. In other words, the data platform must support the nature of scientific work.
Scientific work can be seen as a four step process:
Gather data, including deciding what data is needed
Analyse data, predict outcomes and device alternative courses of action
Perform the most attractive course of action
Monitor effects, gather more data and repeat
This is the approach most professional professions use, it be medical doctors, car mechanics, detectives, geo-scientists, airline pilots, intelligence service officers, etc. Analysis can involve inductive, abductive reasoning dependent of context and problem at hand. Be aware that any reasoning, judgement and classification depends trustworthy data. Without trustworthy data, no trustworthy course of action.
The tale of a rock
The OSDU™ Data Platform support scientific workflows and the best way to describe what that entails is to provide an example, so here we go.
Below a picture of a rock that I found many years ago. At the first glance a fact sheet can be made capturing observable basic facts such as location found, density (weight/volume) and the camera (sensor) used to make the image. Further that it contain quartz (white), olivin (green) and a body that most likely is eclogite (lay man’s work).
Since the stone have several areas of interest and is a 3 dimensional object several images is needed. The easiest way to deal with the images is to place them in a cleverly named file folder and create fact sheet in a database, referencing the image folder and the physical archive location.
Areas of interests are photographed and classified in more detail. Where should the classification be stored? A separate database table could work, but as our needs grow what began as a simple thing become unmanageable as new needs emerge. One physical stone has become multiple independent digital artefacts and we are knee deep attempting to answer “what is one thing?”. Add to the problem that in the real world we do not have a handful of datasets, but thousands. Equinor’s Volve dataset counts 40.000 files.
The OSDU™ Data Platform is made for this kind of problem as can be seen in the next picture. The OSDU™ Data Platform includes a content store (files), a catalogue store (documents) and a search engine (Elastic).
In this case content is stable. The rock does not change, but our understanding of the rock derived from images might change. Lets say that we become interested in the main body of the rock. Then we can go back to the original, make a new sample and add it to the structure. We have derived new insight from existing data and captured it as shown in the diagram below.
The diagram show how a third sample has been added to the story and in addition a interpretation has been derived and linked to the area. The model captures the insights as it emerge. This is the core of the scientific work. It can be argued that the OSDU™ Data Platform is a knowledge capture system.
Knowledge capture
The OSDU™ Data Platform is made to capture subsurface knowledge as illustrated in the diagram below. Seismic is acquired for a geographical area through surveys. The end product from seismic surveys are seismic data files that are interpreted using specialist software tools and one of the findings can be a horizon.
Seismic is measured in the time domain and that implies that the depth of the horizon require correlation with markers from a well log as shown to the left of the diagram. Markers are made when the wellbore is drilled and can be backed by the cuttings that come out of the borehole.
There are two main takeaways from this diagram. Firstly, datasets in terms of log files, rock images and seismic images are contextualised by a domain specific catalogue structure. Secondly, as data is analysed and knowledge is derived in terms of markers and horizons, the insights are managed as data. This is by the way an example of how causal inference works out in practice.
As time goes by and new well bores are made, new seismic surveys conducted both the amount of raw data grows as does the derived knowledge from the data. This takes us to the two most important capabilities provided by the OSDU™ Data Platform, lineage aka provenance and immutability.
Lineage enables provenance, basically that we know what data was used as source for a horizon and marker. Provenance is the key to trustworthy information. As new data emerge, old insights are not deleted but replaced by a new instance that is linked to the previous instance. This mean that the platform can hold multiple copies of the horizon and markers in the diagram above and capture how the understanding of the underground has evolved over time.
The end
The reader should now have a feel with the basic capabilities provided by the OSDU™ Data Platform including some of its scientific fundament. It should also be clear that its more than a data platform. Its really better understood as a knowledge capture system that contextualises data into information that can be reasoned about and used to support decisions while maintaining provenance.
Further the OSDU™ Data Platform resolves som of the hardest parts of earth science and earth modelling as well as being faced with one of computer sciences hardes questions, what is one thing? These are topics that will be revisited.
Hopefully you as reader have enjoyed the journey and I can promise that more stuff will follow. Finally, I hope that the readers see the potential of both technology and approach for other sectors than earth science.
The motivation for data-less (micro) services is found in data gravity, the laws of scale and a doze of thermodynamics. All of them a mouthful in their own way, so lets begin.
Data gravity describes how data attracts data in the same way as celestial bodies attracts each other. The more data there is, the stronger the pull. Data gravity has the power to tranform the best architected software systems into unmanageable balls of mud (data & code). What is less understood is data gravity’s underpinning cause that, my claim, can be traced to the universal laws of scale as outlined by professor Geoffrey West in his book Scale, the universal laws of life and death in organisms, cities and companies. For those who do not have the time to read the book, watch one of his many online talks.
In biology each doubling of size leads to an 75% efficiency gain. The effect being that an elephant burn fewer calories pr. kg than a human, who in turn burn less than a mouse as illustrated below.
Source: Scale
Cities follow the same pattern, but with the factor of 85%. Basically does a big city have fewer gas stations pr inhabitant than a small one. Another aspect is the super-linear scaling of innovation, wages, crime etc that comes from the social networks. This grows with a factor of 15% pr doubling in size.
According to professor West the scaling effects are caused by the fractal nature of the infrastructure that provides energy and removes waste. Think about the human circulatory system and the water, sewage, and gas pipes in cities. I am convinced the same laws apply for software system development, though with different and yet unknown factors.
Last but not least, software development as any activity that uses energy to create order will cause disorder somewhere else. This is due the the second law of thermodynamics. This mean that we need to carefully decide where we want order and how we can direct disorder to places where harm can be minimised.
Data less services:
Data-less services is the natural result of acknowledging the wisdom of the old saying that data ages like wine, software like fish. The essence being that software, the code, the logic, and the technology deteriorate with time, while data can be curated into something more valuable with time.
Therefore it make sense to keep code and data separated. Basically, to separate fast moving code from the slow moving data as a general design strategy. Another way of viewing this is to regard data the infrastructure that scale sub-linear, while the code follows the super-linear growth of innovation.
At first glance this might look like a contradiction in context of the micro-service architectural style that advocates small independent autonomous services. But when we acknowledge that one of the problems with micro-services is sacrificed data management it might make sense.
It is also worth mentioning that separation of code from data is at the heart of the rational agent model of artificial intelligence as outlined in Russel & Norvig’s seminal book Artificial Intelligence: A modern approach where an agent can be anything that can perceive and act upon its environment using sensors and actuators.
A human agent have eyes, ears and other organs for sensing, and hands, legs and voice as actuators. A robotic agent uses a camera, radar or lidar for sensing and actuates tools using motors. A software agent receives files, network packages, keyboard inputs as its sensory inputs and acts upon its environment by creating files, displaying information, sending information to other agents and so on.
The environment could be anything, from the universe to the stock market in Sidney, or a patients prostata that undergo surgery. It can be a physical reality or a digital representation of the same. The figure below shows agent and its environment. An agent consists of logic and rules and the environment consists of data.
Agent and Environment
The internal function of the agent is known as its perception-action cycle. This can be dumb as in a thermostat or highly sophisticated as in a self driving car. While agent research is about the implementation of the perception-action cycle we chose to look at the environment and the tasks the agent need to perform to produce its intended outcomes in that environment.
If the agent is a bank clerk and the environment a customer account, the agent need to be able to make deposits, withdrawals and account statements showing the balance. The environment need to contain the customer and the account. Since the protocol between agent and environment is standardised by an API, agent instances can be replaced by something that is more sophisticated that can take advantage of a richer environment. The customer account represents a long lived asset for the bank and it can be extended to cover loans as well as funds.
Since Information systems are governed by gravity and the laws of scale they are hard to conquer since it at any crossroad is so much easier to extend something that exists then building something new from scratch. Hard enforcement of physical boundaries using micro-services comes with caveats. One being distributed data management, another being that each micro-service will begin to grow in size as new features are needed and therefore require continuous shepherding and fire extinguishing as the entropy materialises.
The proposed approach is to address this using a data-less service architecture that is supported by a shared data foundation in the same way as agents and environment using the blackboard pattern. This mean to implement an architectural style that builds on the old saying that code ages like fish and data ages like wine.
This is by the way the pattern of the OSDU Data Platform that will be addressed in a later post.