The OSDU® Data Platform (hereafter called “the data platform”) has evolved a lot since The OSDU® Data Platform – A Primer was written back in January 2023. It has more than enough functionality that can be used, and it is commercially available from your favourite cloud service provider.
The intent with this blogpost is to explore and expand our thinking on the role of a data platform as a key component in a larger digital ecosystem.
Recap of core concepts
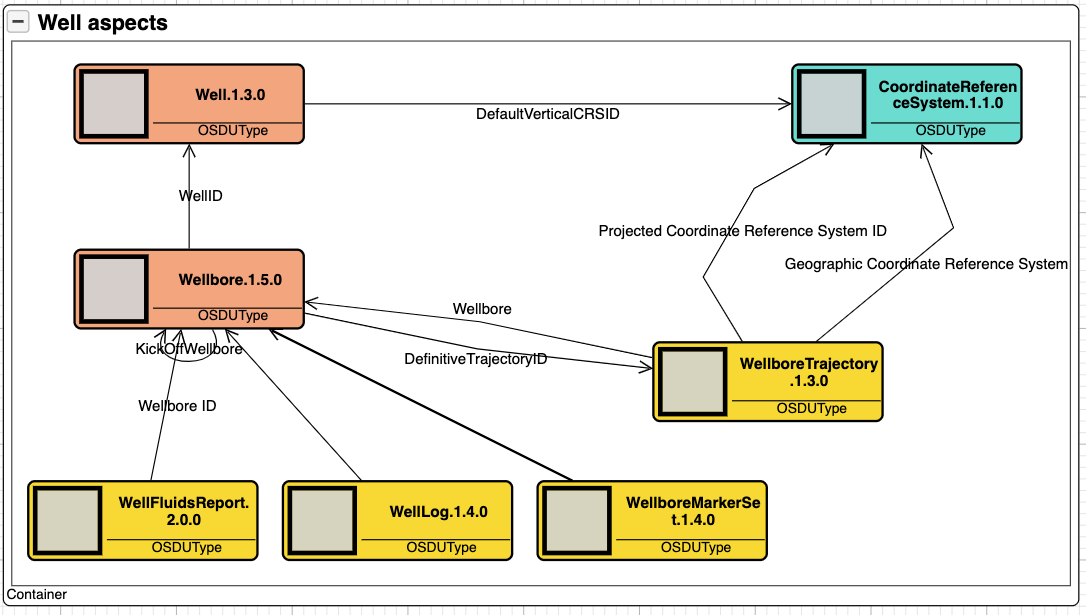
The foundation of the data platform is the data classification schema and design philosophy that is illustrated by using entities from the wells domain (figure 1). Master data objects are orange, reference data is turquoise, and work product components are yellow.
Master data entities represents real world things or concepts that have lifecycles. It is possible to think about master data entities as scaffolding’s or coat hangers, i.e., as object that act as the conceptual bearers in a domain. Work product components provide meta data about datasets that are connected to the actual master entities. Example, when a new fluids report is made and ingested into the data platform, a new fluids report work-product-component entity instance is made and connected to the actual wellbore.
Reference data represent concepts that are stable over time such as coordinate reference systems, units of measure, and various codifications such as country codes. Reference data are often defined by standards and might includes transformation services such as going from metric to imperial units and vice versa. The data platform has a rich set of reference data structures defined, the Coordinate Reference System (CRS) being one of them.
Figure 1: Data concepts in the wells domain
Figure 1 tells the reader that the wells domain has two concepts; well and wellbore. That all wells are geolocated and that the wellbore is the aggregator of associated datasets such fluid reports, logs, markers and trajectories. Lastly that trajectories come with some additional features that we leave as is for now.
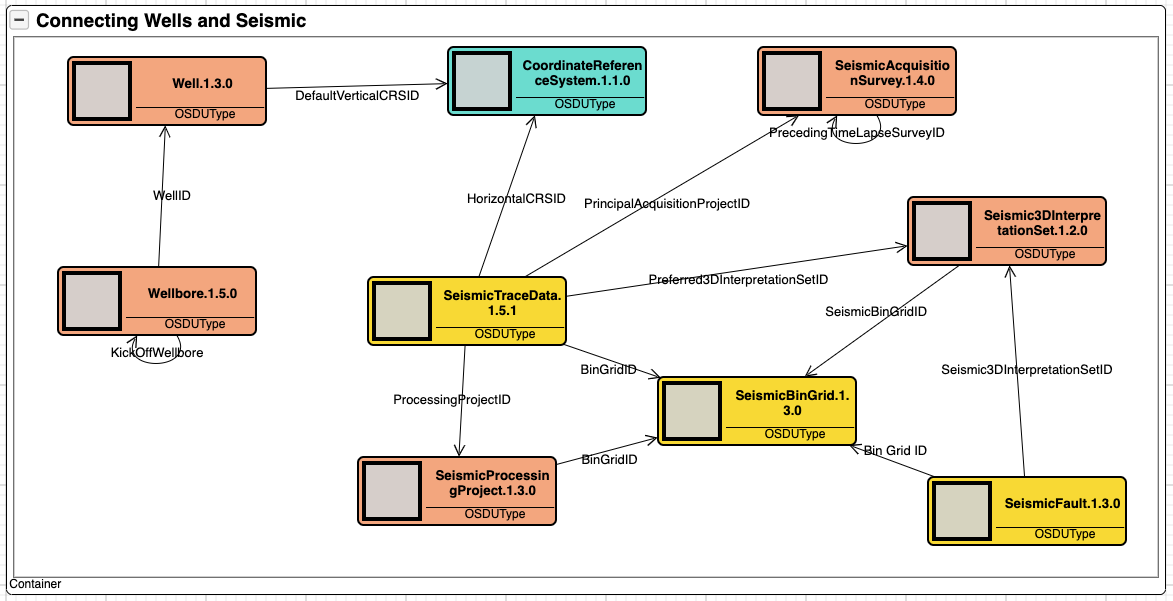
Figure 2 shows how independent domains such as wells and seismic can be related by use of geolocation (CRS). This is extremely useful when we want to know what wells exist in an area covered by a seismic survey.
We can also see how the seismic domain is organised into three fundamental concepts; the acquisition survey; the processing project; and the interpretation set. Further, that the seismic domain consists of three data sets; trace data, bin grids and interpreted faults. What these concepts mean is out of scope as there are much more to both wells and seismic than shown here. Finally, these two figures shows the value of visualisation when exploring the data platform. The tool used is Kava’s AKM Modeller.
Figure 2: Connecting domains through geolocation
The OSDU® data models covers most of the subsurface work. Beginning with seismic acquisition, processing and interpretation. Crossing into structural and dynamic earth modelling, field development planning, well architecting and delivery, including geological and petrophysical evaluation. Further down the road we find production planning and optimisation where the current support is limited.
The subsurface data models are now so good that the mining industry has started to explore them. It should not take much fantasy to see how the data platform can be extended into adjacent domains that manage geolocated hazards and assets. Examples include civil infrastructure such as railroad tracks, roads, water and energy infrastructure, or for that matter, medical records about patients, deceases, and treatments. The key being its easier to repurpose something that works than starting from scratch.
Data work
So far the thinking and discussions about the OSDU® Data Platform has been as a technical product that create value through its existence. In many ways this viewpoint has served us well during development of the technical capabilities, but it might fall short when we want to understand how does it create value for the end user organisations.
The catch of cause is that the data platform does not exist in a vacuum. To create value for its users, they be oil and gas companies or software companies the data platform will be part of a larger functional information system. An information system is much more than its technological components. Literature defines an information system as a formal socio-technical, organisational system designed to collect, process, store and distribute information. From this definition is it obvious that it is a complete different task to develop and implement an information system than developing its technical components.
One way to better understand an information system is by exploring data work, and how such work unfolds in an industrial context. Here will we lend ourself on the work done by the NTNU researchers Parmiggiani et al that is captured in their 2022 article In the Backrooms of Data Science where we can read:
“Much Information Systems research on data science treats data as pre-existing objects and focuses on how these objects are analyzed. Such a view, however, overlooks the work involved in finding and preparing the data in the first place, such that they are available to be analyzed. In this paper we draw on a longitudinal study of data management in the oil and gas industry to shed light on this backroom data work. We find that this type of work is qualitatively different from the front-stage data analytics in the realm of data science, but is also deeply interwoven with it. We show that this work is unstable and bidirectional. That is, the work practices are constantly changing and must simultaneously take into account both what data it might be possible to get hold of as well as the potential future uses of the data. It is also a collaborative endeavour, involving cross-disciplinary expertise, that seeks to establish control over data and is shaped by the epistemological orientation of the oil and gas domain”.
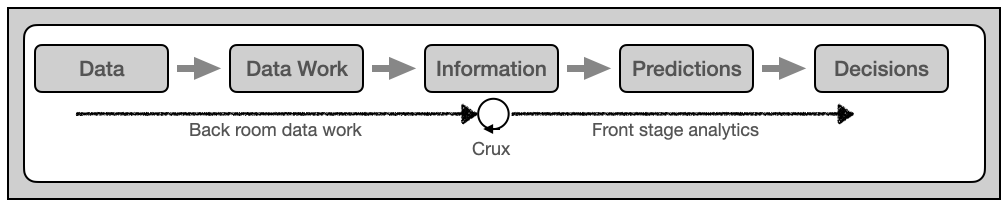
Based on these findings should we begin to think about the OSDU® Data Platform as a component in an information system that support industrial asset lifecycle management and the decision making related to those assets. In such context data work is fundamental for the decision making (figure 3).
Figure 3: From data to decision
The primary function of back room data work is to turn data into information that is fit for purpose for front stage analytics aka data science aka machine learningand AI (Artificial Intelligence). I have deliberately replaced the word analytics by prediction in figure 3. The reason is professor Ajay Agrawal‘s 2017 statement that the value of AI is reduced prediction cost. Cheaper predictions provides options, and options is what is judged when decisions are made.
Predictions and options are the workhorses of decision making, and subsurface workflows, done by hand or machine is fundamentally about prediction options. We don’t know if a formation contain hydrocarbons before a well has been drilled. And even when it’s drilled the reservoir might be missed by a meter or two. The more an option is backed by quality data the higher probability for success.
This means that the back room data work boils down to implementing the data stewardship that enables the best possible information given the data at hand. It’s directly connected to the prediction making that is based on the information we have, and the underpinning causal relationships that governs the physical world we are part of (liquids flow downwards due to gravity).
In situations we do not have enough information are we left with three options. 1) make the decision on the information we have, and accept the uncertainty. 2) acquire more data if possible. 3) use additional data we have to create a richer foundation. This is where the epistemologicalnature of data work materialise. What additional information can we include and what does that additional information bring to the table with respect to the probability for our hypothesis beeing correct or wrong? This takes us directly to Bayes rule and causal inference, concepts that sits at the core of AI.
The data work challenge can therefore be wrapped up as a need for good data stewardship, and data stewardship requires tools and practice. The OSDU® Data Platform is a tool that enables creation of an information system that simplifies data stewardship, an information system that systematically transform the organisation data into a high value trusted information assets for its users.
Humans have collected, classified, copied, translated, and shared information about transactions and environment since we saw the first light of day. We even invented a function to perform this important task, the library, with the library of Alexandria as one of the most prominent examples from ancient time.
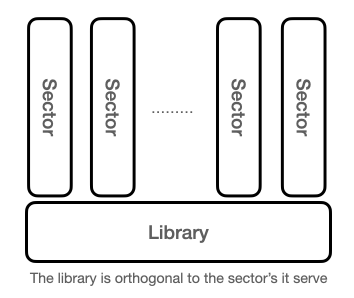
The implementation of the library has changed as a function of technological development while maintaining a stable architecture. The library is orthogonal to the society or enterprise it serve as illustrated in the figure below.
The architectural stability can most likely be explained by the laws of physics. David Deutsch published in 2012 what is now called constructor theory that use contrafactual’s to define what transformations are possible and not. According to the constructor theory of information can a physical system carry information if the system can be set to any of at least two states (flip operation) and that each state can be copied.
This is exactly what the ancient libraries did. The library’s state change when new information arrived allowing the information to be copied and shared. The library works equally well for clay tablets, parchments, papyrus rolls, paper, and computer storage. The only thing that change as function of technology is how fast a given transformation can be performed.
With the introduction of computers the role of the library function changed as many functions migrated into what we can call sector specific applications and databases. In many ways we used computers to optimise sectors at the cost of supporting cross sector interoperability. I think there was a strong belief that technology would make the library redundant.
The effect being that cross sector interaction become difficult. The situation has in reality worsened as each sector has fragmented into specialised applications and databases. What was once an enterprise with five lines of business (sectors) might now be 200 specialised applications with very limited interoperability. This is what we can call reductionism on steroids as illustrated in the figure below.
The only companies who have benefitted from this development are those who provide application integration technology and services. The fragmentation was countered by what I like to call the integrated mastodonts that grew out from what once was a simple database that has been extended to cover new needs. Those might deserve their own blogpost and we leave them for now.
Data platforms
In the mid 1990ties the Internet business boom began. Amzon.com changed retail and Google changed search as two examples. A decade later AWS provided data center services on demand, Facebook and social media was born, and in 2007 Apple launched the iPhone, changing computing and telephony forever.
Another decade down the road, around 2015, the digitalisation wave reached the heavy-industry enterprise space. One of the early insights was the importance of data and the value of making data available outside existing application silos. Silos that had haunted the enterprise IT landscape for decades. By taking advantage of the Internet technology serving big data and social media application the industrial data platform was born.
The data platform made it easier to create new applications by liberating data traditionally stored in existing application silos as illustrated below. The sharp minded should now see that what really took place was reinventing the library as a first order citizen in the digital cityscape.
The OSDU™ Data Platform initiative was born on the basis of this development where one key driver was the understanding that a data platform for an industry must be standardised and its development require industry wide collaboration.
Data platform generations
We tend to look at technology evolution as a linear process, but that is seldom the case. Most often the result of evolution can be seen as technological generations, where new generations come into being while the older generations still are in existence. This is also the case when it comes to data platforms.
Applied on data platforms the following story can be told:
First generation data plattforms followed the data lake pattern. Here application data was denormalised and stored in an immutable data lake enabling mining and big data operations.
Second generation data plattforms follows the data mesh pattern taking advantage of managing data as products by adding governance.
Third generation data platforms take advantage of both data lake and data mesh mechanisms but what make them different is their support of master data enabled product lifecycle management.
Master data is defined by the DAMA Data Management Body of Knowledge as the entities that provide context for business transactions. The most known examples includes customers, products and the various elements that defines a business or domain.
Product lifecycle management models
Master data lifecycle management implies capturing how master data entities evolve with time as the their counterparts in the real world change. To do so a product model is required. The difference between a master data catalogue and a product model is subtle but essential.
A master data catalogue contextualise data with the help of metadata. A product model can also do that, but in addition it captures the critical relationships in the product structure as a whole and tracks how the product structure evolve with time. Using the upstream oil and gas model below the following tale can be told.
When a target (pocket with hydrocarbons) shall be realised a new wellbore must be made. When there are no constraints there can be thousand possible realisations. As the number of constraints are tightened the number of options are reduced and in the end the team land on one that is preferred, while keeping the best options in stock in case something unforeseen happens. Let’s say that the selected well slot breaks and can’t be used before it is repaired, a task that take 6 months. Then its possible for the team to go back to the product model and look for alternatives.
Another product model property is that we can go back in time and look at how the world looked like at a given day. In the early days of a field its possible to see that there was an area where we had seismic that looked so promising that exploration wells was drilled, leading to the reservoir that was developed and so on. The product model is a time machine.
Our example product model above is based on master data entities from upstream oil and gas, entities that are partly addressed by the OSDU™ Data Platform. There are two reasons for using the OSDU™ Data Platform as an example.
Firstly, I work with its development and have reasonably good understanding of the upstream oil and gas industry. Secondly, the OSDU™ Data Platform is the closest I have seen that can evolve into a product lifecycle centric system. The required changes are more about how we think as we have the Lego bricks in place.
Think of the OSDU™ Data Platform as a library of evolutionary managed product models, not as only a data catalogue. Adapt the DDMS (Domain Data Management Services) to become work spaces that operates on selected aspects of the product models, not only the data. The resulting architecture is illustrated below.
Moving to other sectors the same approach is applicable. A product model could could be organised around patients, deceases and treatments or retail stores and assortments for that matter. The crux is to make the defining masters of your industry the backbone of the evolutionary product model.
This story will be continued in a follow-up where the more subtle aspects will be explored. One thing that stand out is that this make it easier to apply Domain Driven Design patterns as the library is a living model, not only static data items.
Hopefully if you have reached to this sentence, you have some new ideas to pursue.
The OSDU™ Data Platform is the most transformative and disruptive digital initiatives in the energy industry. Never before have competitors, suppliers and customers joined forces to solve a common set of problems taking advantage of open-source software licensing, agile methods and global collaboration.
Originally OSDU was an acronym for Open Subsurface Data Universe, directly derived from Shell’s SDU (Subsurface Data Universe) contribution. There is great video presenting Shell’s story that can be found here. The OSDU™ Forum decided to remove the binding to the subsurface and to register OSDU as trademark owned by The Open Group paving the way for adaptation beyond subsurface, enabling constructs like:
OSDU™ Forum – the legal framework that govern community work
OSDU™ Data Platform – the product created by the forum
The OSDU™ Forum’s mission is to delivers an open-source, standards-based, technology-agnostic data platform for the energy industry that:
stimulates innovation,
industrialises data management, and
reduces time to market for new solutions
The mission is rooted in clearly stated problems related to digitalisation of energy and the journey till today is summarised below:
2016 – 2017
Increased focus on digitalisation, data and new value from data in the oil and gas industry
Oil and gas as companies make digital part of their technology strategies and technical roadmaps
2018-2019:
Shell invites a handful oil and gas companies to join forces to drive the development of an open source, standardised data platform for upstream O&G (the part the find and extract oil and gas from the ground)
The OSDU™ Forum was formally founded in September 2018 as an Open Group Forum based on Shell’s SDU donation as the technical starting point
Independent software companies, tech companies and cloud service providers join. Bringing the cloud service providers onboard was a strategic aim. Without their help commercialisation would become more difficult
July 2019: SLB donates DELFI data services, providing additional boost to the forum.
2020-2021:
Release of the first commercial version – Mercury from a merged code base is made available by the cloud service providers for consumption
2022 and beyond
Operational deployments in O&G companies.
Hardening of operational pipelines and commercial service offerings (backup, bug-fixing)
Continuous development and contribution of new OSDU™ Data Platform capabilities.
The OSDU™ Data Platform was born in the oil and gas industry and it is impossible to explain the drivers without a basic understanding of the industrial challenges that made it, challenges that come from earth science and earth science data.
Earth science
Earth science is the study of planet Earth’s lithosphere (geosphere), biosphere, hydrosphere, atmosphere and their relationships. Earth science forms the core of energy, it be oil and gas, renewables (solar, wind and hydro) and nuclear. Earth science inherently complex because it’s trans-disciplinal, deals with non-linear relationships, contain known unknowns, even unknowable’s, and comes with a huge portion of uncertainty.
Hydrocarbons forms in the upper part of earth’s lithosphere. Dead organic material is transported by rivers to lakes where it sink and is turned into sediments. Under the right conditions the sediments become recoverable hydrocarbons by processes that takes millions of years. In the quest for hydrocarbons geo-scientists develop models of earths interior that help them to predict where to find recoverable hydrocarbon.
Earth models
Earth models sits at the core of the oil and gas industries subsurface workflows and are used to find new resources, develop reservoir drainage strategies, investment plans, optimise production and placement of new wells. Earth models are used to answer questions like:
How large hydrocarbon volumes exists?
How is the volume placed in the reservoir?
How much is recoverable in the shortest possible time?
As reservoirs empties, where are the remaining pockets?
How much has been produced, from when, and how much remains?
How to drain the volumes as cost efficient as possible?
Earth models are developed from seismic, observations (cores, well logs and cuttings) and produced volumes. When exploring new areas access to relevant datasets is an issue. Exploration wells are expensive and finding the best placement is important. Near-field exploration is easier as the geology is better known. Some production fields use passive seismic monitoring allowing continuous monitoring of how the reservoir changes while being drained. Another approach is 4D seismic, where new and old seismic images are compared.
Seismic interpretation means to identify geological features such as horizons and faultsand to place them at the appropriate place in a cube model of the earth. How this is done is shown in this 10 minute introduction video.
The pictures to the left shows a seismic image. To derive useful information requires special training as it is a process of assumptions and human judgement. To the right a picture of log curves and for more information about well logging please read this. Seismic datasets are very large and relatively expensive to compute. Well logs are smaller in size, but they come in huge numbers and choosing the best one for a specific task might be a time consuming process.
Timescales
Oil and gas fields are long-lived and the longevity represents a challenge on its own that is best illustrated using an example. The Norwegian Ekofisk field, discovered in 1969, put on stream in 1971, and expected to produce for another 40 years. The catch being that data acquired with what is regarded state of art technology will outlive the technology. Well logs from the mid sixties, most likely stored on paper are still relevant.
Adding to the problem is the changes in measuring method and tool accuracy. This is seen when it comes to metrological data. Temperature measured with a mercury gauge come with an accuracy of half degree celcius. Compare that with the observed temperature rise of one degree over the last hundred years. Being able to compare apples with apples become critical and therefore is additional sources of data required.
When the storage technology was paper this was one thing, now when we storage has become digital its something else. For the data to be useful a continuous reprocessing and re-packeting is required.
Causal inference
Subsurface work, as other scientific work is based on causal inference i.e., asking and answering questions attempting to figuring out the causal relationships in play.
The Book of Why defines three causation levels seeing, doing and imagination as illustrated by the figure below.
Source: The Book of Why
Seeing implies observing and looking for patterns. This is what an owl do when it hunts a mice, and it is what the computer does when playing the game of Go. The question asked is; what if I see… eluding to that if something is seen it might impact the probability for something else to be true. Seismic interpretation begins here with asking where are the faults while looking at the image.
Doing implies adding change to the world. It begins by asking what will happen if we do this? Intervention ranges higher than association because it involves not just seeing but changing what is. Seeing smoke tells a different story than making smoke. Its not possible to answer questions about interventions with passively collected data, no matter how big the data set or how deep the neural network. One approach to do this is to perform an experiment, observing the responses. Another approach is to build a causal model that captures causal relationships in play. When we drill a new well that can be seen as an experiment where we both gather rung one data, and also discover rung 2 evidence related to what work and what does not work. The occurrence of cavings and a potential hole collapse being one example.
A sufficient strong and accurate causal model can allow us to use rung one (observation) data to answer rung two questions. Mathematically this can be expressed as P(cake | do (coffee)) or in plain text, what will happen to our sales of cake if we change the price of coffee.
Imagination implies asking questions like my headache is gone, but why? Was it the aspirin I took? The food I ate? These kind of questions takes us to counterfactuals, because to answer them we must go back in time, change the history and ask, what would have happened if I had not taken the aspirin? Counterfactuals have a particularly problematic relationship with data because data is by definition facts. Having a causal model that can answer counterfactual questions are immense. Finding out why a blunder occurred allow us to take the right corrective measures in the future. Counterfactuals is how we learn. It should be mentioned that laws of physics can be interpreted as counterfactual assertions such as “had the weight on the spring doubled, its length would have doubled” (Hooke’s law). This statement is backed by a wealth of experimental (rung 2) evidence.
By introducing causation the value of useful data should be clear. Without trustworthy data, that we are not able to agree about what we can see, there cant be any trustworthy predictions, causal reasoning, reflection and action. The value of a data platform is that it helps with the data housekeeping at all levels. Input and output from all the three rungs can be managed as data.
Causal models are made from boxes and arrows as illustrated in the figure below. How the factors contributes can be calculated as probabilities along the arrows. The beauty of causal models is that their structure is stable, while the individual factors contribution will change. Loss mean that mud leaks into the formation due to overpressure, and gain implies that formation fluids leaks into the wellbore. Both situations are undesired as they might lead to sever situations during drilling.
Finally, dynamic earth modells based on fluid dynamics captures causal relationships related to how fluids flow in rock due to the laws of physics.
Digitalisation
Until less than 60 years ago earth models as most other models was paper based. With the development of computers earth models have become digital with raw data and derived knowledge carved into software and databases.
Despite digital tooling earth science work practice has not changed much. Scientists collects data, build models and hypothesis, analyse and predict possible outcomes.
One thing that has changed is the amount of data. The dataset shared by Equinor for the retired Volve field consists of 40.000 files. Volve was a small field producing for a decade. To know what dataset can / should / could be used for what type of work is not trivial.
Another challenge is that each discipline has its own specialist tools emphasising different aspects of the dataset. This mean that two disciplines will struggle to synthesise their results at the end. Adding to the challenge the fact that models are tied to the tool and the individual users preferences and understanding.
The result is an individ centred, discipline specific tooling that make a holistic (trans disciplinary) view difficult if at all possible. Said in other words: we have tools the forest, tools for the threes and tools for the leaves, but no tool that allow us to study threes in context of the forest or leaves in context of a three. Philosophically speaking is this the result of applying reductionism on a complex problem.
The effect is fragmentation and inconsistency across individuals, tools, disciplines and organisational units leading to loss of knowledge, loss of trust and continuously rework as people struggle to build on each others work.
Fragmentation is a good starting point for the next topic that create a lot of pain when building digital data models, the question of what is one thing and when does a thing change so much it become a new thing.
One thing
According to William Kent in Data and Reality answering what is one thing forces us to explore three key concepts:
Oneness. What is one thing?
Sameness. When we say two things are the same, or the same thing? How does change affect identity?
Categories. What is it? In what categories do we perceive the thing to be? What categories fo we acknowledge? How well defined are they?
Oneness underlies the general ambiguity of words and we will use an example from the book regarding the word “well” as used in the files of an oil company.
In their geological database, a “well” is a single hole drilled in the surface of the earth, whether or not it produces oil. In the production database, a “well” is one or more holes covered by one piece of equipment, which has tapped into a pool of oil. The oil company had trouble integrating these databases to support a new application: the correlation of well productivity with geological characteristics.
This imply that the word well is ambiguous across contexts. Observe that the ambiguity lays with the understanding of the concept well. The production database might have used the term well for what a geologist might think of as a wellbore.
What we observe here is ambiguity across contexts. The production database might have used the term well for what a geo-scientist might think of as a wellbore. Reading along we find this:
As analyst and modellers, we face “oneness”, “sameness” and “categories”. Oneness means coming up with a clear and complete explanation of what we are referring to. Sameness means reconciling conflicting views of the same term, including whether changes (and what type of changes ) transform the term into a new term. Categories means assigning the right name to this term and determining whether it is an entity type, relationship, or attribute on a data model. Oneness, Sameness and Categories are tightly intertwined with one another.
The main takeaway from this is that the ambiguities that we find in a trans-disciplinary fields such as earth science will create problems if not properly addressed. These ambiguities has more to do with how disciplines thinks and express themselves than finding a digital representation. The challenge sits with the semantics of language.
The value of standardising terminology is seen in medicine and anatomy where every piece of the human body is given a latin name that is thought and used across disciplines.
Contextualisation
Domain Driven Design provide two architectural patterns; Bounded Context and Context Mapping that help software architects and data modellers to create explicit context and context relationships. Bounded contexts and context maps allows architects to practice divide and conquer without loosing the whole. Reconciling might prove to be much harder than first thought. The picture below shows practical use of how bounded contexts can be applied on the well problem described above.
By modelling the two applications as bounded context it become clear that reconciliation will require use of a new context as forcing one applications definition on the other will not work. Therefore is it better to create a new bounded context that reconcile the differences by introducing new terminology.
The role of a data platform
A data platforms store, manage and serve data to consumers while adhering to the governance rules defined for the data. A data platform is not a database, but it can be build using data base technology. A data platform must also address the problems that come from semantic ambiguity (what is one thing), support the timescales and complexities found in the physical world, and the reality that both the physical world as well as its digital representation change with time. In other words, the data platform must support the nature of scientific work.
Scientific work can be seen as a four step process:
Gather data, including deciding what data is needed
Analyse data, predict outcomes and device alternative courses of action
Perform the most attractive course of action
Monitor effects, gather more data and repeat
This is the approach most professional professions use, it be medical doctors, car mechanics, detectives, geo-scientists, airline pilots, intelligence service officers, etc. Analysis can involve inductive, abductive reasoning dependent of context and problem at hand. Be aware that any reasoning, judgement and classification depends trustworthy data. Without trustworthy data, no trustworthy course of action.
The tale of a rock
The OSDU™ Data Platform support scientific workflows and the best way to describe what that entails is to provide an example, so here we go.
Below a picture of a rock that I found many years ago. At the first glance a fact sheet can be made capturing observable basic facts such as location found, density (weight/volume) and the camera (sensor) used to make the image. Further that it contain quartz (white), olivin (green) and a body that most likely is eclogite (lay man’s work).
Since the stone have several areas of interest and is a 3 dimensional object several images is needed. The easiest way to deal with the images is to place them in a cleverly named file folder and create fact sheet in a database, referencing the image folder and the physical archive location.
Areas of interests are photographed and classified in more detail. Where should the classification be stored? A separate database table could work, but as our needs grow what began as a simple thing become unmanageable as new needs emerge. One physical stone has become multiple independent digital artefacts and we are knee deep attempting to answer “what is one thing?”. Add to the problem that in the real world we do not have a handful of datasets, but thousands. Equinor’s Volve dataset counts 40.000 files.
The OSDU™ Data Platform is made for this kind of problem as can be seen in the next picture. The OSDU™ Data Platform includes a content store (files), a catalogue store (documents) and a search engine (Elastic).
In this case content is stable. The rock does not change, but our understanding of the rock derived from images might change. Lets say that we become interested in the main body of the rock. Then we can go back to the original, make a new sample and add it to the structure. We have derived new insight from existing data and captured it as shown in the diagram below.
The diagram show how a third sample has been added to the story and in addition a interpretation has been derived and linked to the area. The model captures the insights as it emerge. This is the core of the scientific work. It can be argued that the OSDU™ Data Platform is a knowledge capture system.
Knowledge capture
The OSDU™ Data Platform is made to capture subsurface knowledge as illustrated in the diagram below. Seismic is acquired for a geographical area through surveys. The end product from seismic surveys are seismic data files that are interpreted using specialist software tools and one of the findings can be a horizon.
Seismic is measured in the time domain and that implies that the depth of the horizon require correlation with markers from a well log as shown to the left of the diagram. Markers are made when the wellbore is drilled and can be backed by the cuttings that come out of the borehole.
There are two main takeaways from this diagram. Firstly, datasets in terms of log files, rock images and seismic images are contextualised by a domain specific catalogue structure. Secondly, as data is analysed and knowledge is derived in terms of markers and horizons, the insights are managed as data. This is by the way an example of how causal inference works out in practice.
As time goes by and new well bores are made, new seismic surveys conducted both the amount of raw data grows as does the derived knowledge from the data. This takes us to the two most important capabilities provided by the OSDU™ Data Platform, lineage aka provenance and immutability.
Lineage enables provenance, basically that we know what data was used as source for a horizon and marker. Provenance is the key to trustworthy information. As new data emerge, old insights are not deleted but replaced by a new instance that is linked to the previous instance. This mean that the platform can hold multiple copies of the horizon and markers in the diagram above and capture how the understanding of the underground has evolved over time.
The end
The reader should now have a feel with the basic capabilities provided by the OSDU™ Data Platform including some of its scientific fundament. It should also be clear that its more than a data platform. Its really better understood as a knowledge capture system that contextualises data into information that can be reasoned about and used to support decisions while maintaining provenance.
Further the OSDU™ Data Platform resolves som of the hardest parts of earth science and earth modelling as well as being faced with one of computer sciences hardes questions, what is one thing? These are topics that will be revisited.
Hopefully you as reader have enjoyed the journey and I can promise that more stuff will follow. Finally, I hope that the readers see the potential of both technology and approach for other sectors than earth science.