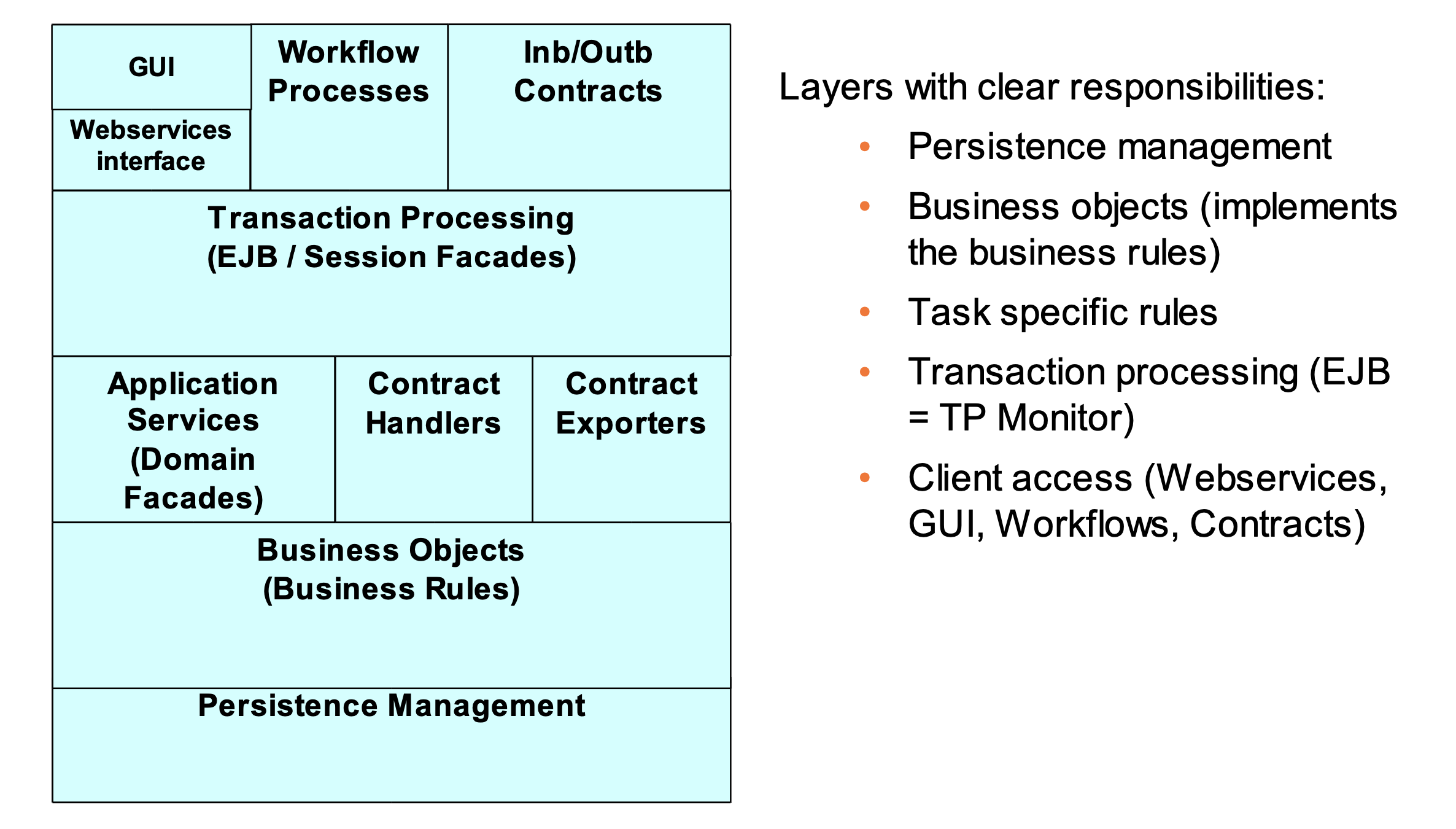
Separation of concern is a key design principle. Just like our homes have different rooms for different purposes. In computer science, seperation of concern leads to modularization, encapsulation, and programming language constructs like functions and objects. It’s also behind software design patterns like layering and model-view-controller (MVC).
The importance of breaking software down into smaller loosley coupled parts with high cohesion have been agreed for decades. Yourdon & Constantine’s 1978 book Structured Design: Fundamentals of a Discipline of Computer Program and System Design provides fundamental thinking on the relationships between coupling, cohesion, changability and software system lifecycle cost.
Modularization begins with the decomposition of the problem domain. For digital information systems (software) it continues with identification of abstractions that match both the problem domain and the execution machinery, and the packaging of these abstractions into working assemblies aka applications that can run on a computer.
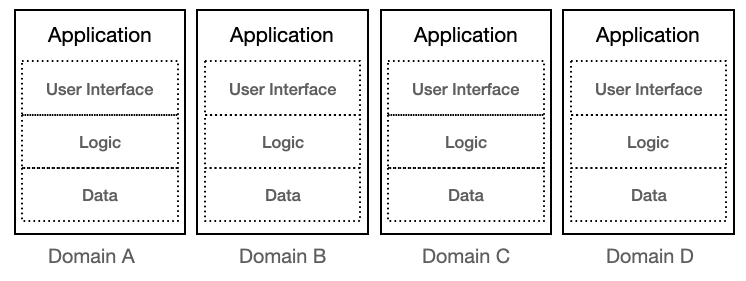
Figure 1 shows that each application addresses three concerns: the user interface, the functional logic, and its data. While software architects talk about their systems using such strict layering, everybody who have looked inside a real-world applications know reality is much more muddy.
What figure 1 does not show is how a company is divided into different areas, and how these areas are used to define which applications are responsible for which tasks. It also doesn’t explain how information can be exchanged between applications, and it doesn’t illustrate how data gravity corrupts even the best design as time goes by. That what began as a well-defined application over years becomes an entangled unmanagable behemoth.
Separating the wrong concerns?
When we try to figure out why certain things are missing, we need to ask a key question about how we design business applications: Are we dividing things up in the best way? To answer this, we have to think about the different factors at work and consider different ways to deal with them.
Data gravity captures the hard fact that data gravitates data. Why this is so has many reasons. Firstly, it’s always easier to extend an existing database with a new table than making a new one from scratch. The new table can leverage the values of existing tables in that database. In other words, it makes data exchange simpler. Finally, the energy cost of adding a new table is lower than the energy cost of creating a complete new database and establishing required exchange mechanisms.
Enterprises are complex systems without boundaries. Organisational charts show how the enterprise is organized into verticals such as sales, engineering, and manufacturing, verticals that are served by horizontals such as IT and finance and control. In reality, the enterprise is a web of changing interactions that continuously consume and produce data. Mergers, divestments, and reorganizations change the corporate landscape continuously, adding to the underpinning complexity.
Applications are snapshots of the enterprise. They represent how the enterprise works at a given point in time and as such, they are pulled apart by data gravity on one side and the enterprise dynamics on the other. This insight is captured by the old saying that data ages as wine, and software ages as fish. Using the wine and fish analogy, applications are best described as barrels with fish and wine.
The effects of these forces play over time is entangled monolithic behemoth applications that are almost impossible to change and adapt to new business needs. The microservices architectural style was developed to deal with this effect.
Microservices
Microservices is based on decomposing the problem space into small independent applications that communicates using messaging. The approach is reductionistic and driven by development velocity. One observed effect is distributed data management, and they does not solve the underpinning problem of data and software entanglement.
The specific relevant content for this request, if necessary, delimited with characters: Sticking to the fish analogy, microservices enable us to create small barrels that contain Merlot and salmon, Barbera and cod, and Riesling and shark, or whatever combination you prefer. They do not separate data from the code, quite the opposite, they are based on data and software entanglement.
The history of the microservice architectural style goes back to 2011-2012, and for the record, the author was present at the 2011 workshop. It’s also important to mention that the style has evolved and matured since its inception, and it is not seen as a silver bullet that solves everything that is bad with monoliths. It’s quite the opposite; microservices can lead to more problems than they solve.
To get a deeper and more profound understanding of microservices read Software Architecture: The Hard Parts and pay attention to what is defined as architectural quanta: an independently deployable artifact with high functional cohesion, high static coupling, & synchronous dynamic coupling. The essence of an architectural quanta is independent deployment of units that perform a useful function. A quanta can be built from one or many microservices.
Introducing the library architectural style
The proposed solution to the problems listed above is to separate data from applications and to establish a library as described in the reinventing the library post, and to call this the library architectural style as illustrated by figure 2 below.
The essence of the library style is to separate data from the applications and to provide a home for the data and knowledge management services that are often neglected. The library style is compatible with the microservice style, and in many ways strengthens it as the individual microservice is relieved from data management tasks. The library itself can also be built using microservices, but it’s important that it’s deployed as independent architectural quanta(s) from the application space, which are quantas of their own.

There are many fators that make implementation of a functional library difficult. Firstly, all data stored in the library must conform to the libraries data definitions. Secondly, the library must serve two conflicting needs. The verticals need for efficient work and easy access to relevant data, and the library’s own needs for data inventory control, transformations and processing of data into consumable insigthts and knowledge.
The library protocol
A classical library lending out books provide basically four operations to its users:
- Search i.e., what books exist, their loan status, and where (rack & shelf) they can be found.
- Loan i.e., you take a book and register a loan.
- Return i.e., you return the book and it’s placed back by the librarian.
- Wait i.e., you register for a book to borow and are notified when it’s available.
These operations constitute the protocol between the library and its user, e.g., the rules and procedures for lending out books. In the pre-computer age, the protocol was implemented by the librarian using index cards and handwritten lists. The librarians performed in addition many back-office services such as acquiring new books, replacing damaged copies, and interacting with publishers and so on. These services are left out for now.
Linda, Tuple spaces and the Web
In danger of making this a history lesson, but in 1986 David Gelerntner at Yale University released what is called the Linda coordination language for distributed and parallel computing. Linda’s underpinning model is the tuple space.
A tuple space is an implementation of the associative memory paradigm for parallel / distributed computing where the “space” provides repository of tuples i.e., sequences or ordered lists of elements that can be manipulated by a set of basic operations. Sun Microsystems (now Oracle) implemented the tuple space paradigm in their JavaSpace service that provide four basic operations:
- write (Entry e, ..): Write the given entry into this space instance
- read (Entry tmpl, ..): Read a matching entry from this space instance
- take (Entry tmpl, ..): Read an entry that matches the template and remove it from the space
- notify(Entry tmpl, ..): Notify the application when a matching entry is written to the space instance
Entry objects – define the data elements that a JavaSpace can store. The strength of this concept is that the JavaSpace can store linked and loosely coupled data structures. Since entries are Java objects, they can also be executed by the readers. This makes it possible to create linked data structures of executable elements. An example being arrays whose cells can be manipulated independently.
JavaSpaces is bound to the Java programming language, something that contributed to its commercial failure. Another factor was that around year 2000 few if any enterprises were interested in parallel/distributed computing, nor were the enterprise software suppliers such as Microsoft, Oracle, SAP, and IBM.
The evolution of the Internet has changed this. The HTTP (Hypertext Transfer Protocol) provides an interface quite similar to the one associated with tuple spaces, though with some exceptions:
- GET: requests the target resource state to be transferred
- PUT: incurs changes to the target resource state
- DELETE: requests a deletion of the target resource state
The main difference is that HTTP is a pure transport protocol between a client and a server, where the client can request access to an addressable resource. A tuple space implements behavior on the server side, behavior that could be made accessible on the Internet using HTTP.
Roy Fielding’s doctoral dissertation architectural styles and design of network-based software architectures defines the REST (Representative State Transfer) architectural style that is used by most Web APIs today.
REST provides an abstraction of how hypermedia resources (data, metadata, links, and executables) can be moved back and forth between where they’re stored and used. Most REST implementations use the HTTP protocol for transport but are not bound by it. REST should not be confused with Remote Procedure Calls (RPC) that can also be implemented using HTTP. Distinguishing RESTful from RPC can be difficult; the crux is that REST is bound to access of hypermedia resources.
The JavaSpace API is a RESTful RPC API as its operations are about moving Entry objects between a space and its clients, as shown in figure 3. The implication is that RESTful systems and space-based systems are architecturally close and may be closer than first thought when we explore what a data platform can do.
Data platforms
A data platform is according to ChatGPT a comprehensive infrastructure that facilitates the collection, storage, processing, and analysis of data within an organization. It serves as a central hub for managing and leveraging data to derive insights, make informed decisions, and support various business operations.
The OSDU® Data Platform, as an example, provides the following capabilities:
- Provenance aka lineage that tracks the origin of a dataset and all its transformations
- Entitlement that ensures that only those entitled have access to data
- Contextualisation by sector specific scaffolding structures such as area, field, well, wellbore, survey
- Standardised data definitions and APIs
- Imutability and versioning as the foundation of provenance and enrichment
- Dataset linking by use of geolocations including transformation between coordinate systems
- Unit of measure and transformations between unit systems
- Adaptable to new functional needs by defining new data models aka schemas
The OSDU® Data Platform is an industry-driven initiative aimed at creating an open-source data platform that standardizes the way data is handled in the upstream oil and gas sector. The platform demonstrates how a library can be built. For more details, it can be found on the OSDU® Forum’s homepage. Those needing a deep-dive are recommended to read the primer part one and two.
The OSDU® Data Platform functions in many ways as a collaborative data space. It can also be understood as a system for learning and transfer of knowledge within and between disciplines. It is in many ways a starting point for developing a digital variant of the ancient library where scribes captured and transformed the knowledge of their time for future use.
From JavaSpaces to DataSpaces
JavaSpaces failed commercially for many reasons outside the scope of this blog post. Despite that, the value of space-based computing lives on in initiatives such as the European Strategy for Data and the European Data Space initiative.
The OSDU® Data Platform has demonstrated that it’s possible to create industry-wide data platforms that can act as the foundation in what can be called the library architectural style. A style that is basically a reincarnation of space-based computing.
The true power of space-based computing disappears in technical discussions related to how to construct the spaces, discussions on who owns what data, and so on. What is lost in those discussions is the simplicity space-based computing offers application developers.
A simplicity that is very well illustrated in this quarter of a century-old picture from Sun Microsystems showing how “Duke the JavaBean” interacts with JavaSpace instances moving elements around.
This is also a good example of how a library works; some create new books that are made available in the library. Others wait for books to read, and others take books on a loan. Others work on the backside, moving books from one section (space) to another, or for that matter, from one library to another.

Figure 3 illustrates what this blog post started out with, separation of concern and the importance of separating the right concerns. There is a huge potential in decoupling workers (applications) from the inventory management that is better done by a library.
A digression. My soon 25-year-old master thesis demonstrated that a JavaSpace-based implementation of a collaborative business problem was half the size of the solution built with the more traditional technology of the time. That, in many ways, shows the effect of having a data platform in place and the value from separating data from business logic.
The OSDU® Data Platform work has thought us that the development of an industry wide data platform does not come for free and require collaboration on global scale. The OSDU® Data Platform development has also demonstrated that this is possible within one of the most conservative industries of this world, something that mean its doable in other sectors as well. Their benefit beeing that they can stand on the shoulders of what has already been achieved. A working technological framework is made availble for those who want to explore it.