
Humans have collected, classified, copied, translated, and shared information about transactions and environment since we saw the first light of day. We even invented a function to perform this important task, the library, with the library of Alexandria as one of the most prominent examples from ancient time.
The implementation of the library has changed as a function of technological development while maintaining a stable architecture. The library is orthogonal to the society or enterprise it serve as illustrated in the figure below.
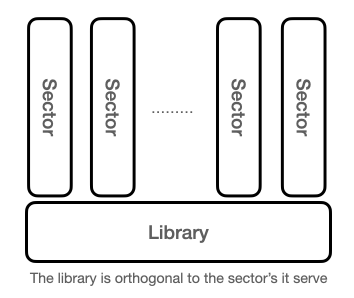
The architectural stability can most likely be explained by the laws of physics. David Deutsch published in 2012 what is now called constructor theory that use contrafactual’s to define what transformations are possible and not. According to the constructor theory of information can a physical system carry information if the system can be set to any of at least two states (flip operation) and that each state can be copied.
This is exactly what the ancient libraries did. The library’s state change when new information arrived allowing the information to be copied and shared. The library works equally well for clay tablets, parchments, papyrus rolls, paper, and computer storage. The only thing that change as function of technology is how fast a given transformation can be performed.
With the introduction of computers the role of the library function changed as many functions migrated into what we can call sector specific applications and databases. In many ways we used computers to optimise sectors at the cost of supporting cross sector interoperability. I think there was a strong belief that technology would make the library redundant.
The effect being that cross sector interaction become difficult. The situation has in reality worsened as each sector has fragmented into specialised applications and databases. What was once an enterprise with five lines of business (sectors) might now be 200 specialised applications with very limited interoperability. This is what we can call reductionism on steroids as illustrated in the figure below.

The only companies who have benefitted from this development are those who provide application integration technology and services. The fragmentation was countered by what I like to call the integrated mastodonts that grew out from what once was a simple database that has been extended to cover new needs. Those might deserve their own blogpost and we leave them for now.
Data platforms
In the mid 1990ties the Internet business boom began. Amzon.com changed retail and Google changed search as two examples. A decade later AWS provided data center services on demand, Facebook and social media was born, and in 2007 Apple launched the iPhone, changing computing and telephony forever.
Another decade down the road, around 2015, the digitalisation wave reached the heavy-industry enterprise space. One of the early insights was the importance of data and the value of making data available outside existing application silos. Silos that had haunted the enterprise IT landscape for decades. By taking advantage of the Internet technology serving big data and social media application the industrial data platform was born.
The data platform made it easier to create new applications by liberating data traditionally stored in existing application silos as illustrated below. The sharp minded should now see that what really took place was reinventing the library as a first order citizen in the digital cityscape.

The OSDU™ Data Platform initiative was born on the basis of this development where one key driver was the understanding that a data platform for an industry must be standardised and its development require industry wide collaboration.
Data platform generations
We tend to look at technology evolution as a linear process, but that is seldom the case. Most often the result of evolution can be seen as technological generations, where new generations come into being while the older generations still are in existence. This is also the case when it comes to data platforms.

Applied on data platforms the following story can be told:
- First generation data plattforms followed the data lake pattern. Here application data was denormalised and stored in an immutable data lake enabling mining and big data operations.
- Second generation data plattforms follows the data mesh pattern taking advantage of managing data as products by adding governance.
- Third generation data platforms take advantage of both data lake and data mesh mechanisms but what make them different is their support of master data enabled product lifecycle management.
Master data is defined by the DAMA Data Management Body of Knowledge as the entities that provide context for business transactions. The most known examples includes customers, products and the various elements that defines a business or domain.
Product lifecycle management models
Master data lifecycle management implies capturing how master data entities evolve with time as the their counterparts in the real world change. To do so a product model is required. The difference between a master data catalogue and a product model is subtle but essential.
A master data catalogue contextualise data with the help of metadata. A product model can also do that, but in addition it captures the critical relationships in the product structure as a whole and tracks how the product structure evolve with time. Using the upstream oil and gas model below the following tale can be told.
When a target (pocket with hydrocarbons) shall be realised a new wellbore must be made. When there are no constraints there can be thousand possible realisations. As the number of constraints are tightened the number of options are reduced and in the end the team land on one that is preferred, while keeping the best options in stock in case something unforeseen happens. Let’s say that the selected well slot breaks and can’t be used before it is repaired, a task that take 6 months. Then its possible for the team to go back to the product model and look for alternatives.
Another product model property is that we can go back in time and look at how the world looked like at a given day. In the early days of a field its possible to see that there was an area where we had seismic that looked so promising that exploration wells was drilled, leading to the reservoir that was developed and so on. The product model is a time machine.

Our example product model above is based on master data entities from upstream oil and gas, entities that are partly addressed by the OSDU™ Data Platform. There are two reasons for using the OSDU™ Data Platform as an example.
Firstly, I work with its development and have reasonably good understanding of the upstream oil and gas industry. Secondly, the OSDU™ Data Platform is the closest I have seen that can evolve into a product lifecycle centric system. The required changes are more about how we think as we have the Lego bricks in place.
Think of the OSDU™ Data Platform as a library of evolutionary managed product models, not as only a data catalogue. Adapt the DDMS (Domain Data Management Services) to become work spaces that operates on selected aspects of the product models, not only the data. The resulting architecture is illustrated below.

Moving to other sectors the same approach is applicable. A product model could could be organised around patients, deceases and treatments or retail stores and assortments for that matter. The crux is to make the defining masters of your industry the backbone of the evolutionary product model.
This story will be continued in a follow-up where the more subtle aspects will be explored. One thing that stand out is that this make it easier to apply Domain Driven Design patterns as the library is a living model, not only static data items.
Hopefully if you have reached to this sentence, you have some new ideas to pursue.

Excellent Summary.
[…] By developing a loosely coupled application or platform based on API’s that can be adapted to changing needs. Loos coupling means that the data management part – the record keeping is separated from end user tools along the lines described here. […]
[…] model according to the EU Data Spaces approach, or by using a centralised model according to the library model. Alternative #1 is tightly coupled and intrusive. Alternative #2 is loosely coupled and […]